

 science-review.ru
science-review.ru
Большие данные [1] – это огромный набор данных со сложной структурой [2]. Такие данные встречаются в различных областях: биология, медицина, социальные сети, аналитика продаж и гуманитарные науки [3]. Наличие в системе большого количества данных накладывает ограничения на применяемые технологии хранения [4] и обработки данных. Обработка большого набора данных является сложной задачей для традиционных инструментов. Поэтому были созданы новые методы, как альтернатива традиционным СУБД и методам Business Intelligence. Сюда можно включить такие средства массово-параллельной обработки неопределенно структурированных данных, как NoSQL решения, библиотеки проекта Hadoop, а также алгоритмы MapReduce. Для анализа больших данных применяются технологии искусственного интеллекта и алгоритмы машинного обучения [5]. Чтобы сделать алгоритм обучения более эффективным и устранить риск переобучения, необходим способ уменьшить размер данных.
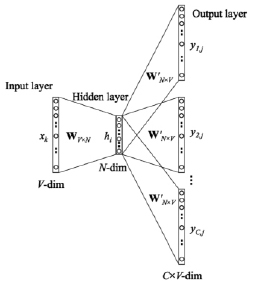
Диаграмма модели Skip-gram
Модель Word2vec [6], созданная Google, представляет собой нейронную сеть, которая обрабатывает текстовые данные. Word2Vec – это не один алгоритм, он включает в себя две модели обучения: «Continuous Bag of Words» (CBOW) и Skip-gram [7, 8]. CBOW – «непрерывный мешок со словами», архитектура, которая предсказывает текущее слово, исходя из окружающего его контекста. Архитектура типа Skip-gram действует иначе: она использует текущее слово, чтобы предугадывать окружающие его слова. Имеется возможность переключаться и делать выбор между алгоритмами. Порядок слов контекста не оказывает влияния на результат ни в одном из этих алгоритмов. На вход в обучающую модель Word2Vec подается текстовый массив данных, а на выходе генерируются векторы слов. Кроме того, Word2Vec имеет возможность вычислять косинусное расстояние между каждым словом. Поэтому выгодно группировать похожие слова на основе их расстояний. Сгруппировав подобные слова, исходный размер данных проецируется на новое, более низкое измерение. На первом этапе в модель Word2Vec подается крупномасштабный текстовый массив данных для создания векторов слов. На следующем этапе для кластеризации этих векторов слов используется алгоритм машинного обучения (K-means) [9], где слова (признаки) группируются в K различных кластеров. Алгоритм k-means разбивает исходное множество объектов на k кластеров так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга.
Выбор числа k может основываться на предыдущих результатах, теоретических основах или интуиции. Если нет предположений относительно этого числа, рекомендуют начинать с меньшего количества, постепенно увеличивая его и сравнивая полученные результаты.
Работа алгоритма состоит из нескольких этапов:
- случайным образом выбрать k точек, являющихся начальными «центрами масс» кластеров;
- отнести каждый объект к кластеру с ближайшим «центром масс»;
- пересчитать «центры масс» кластеров согласно их текущему составу;
- если критерий остановки алгоритма не удовлетворен, вернуться к п. 2.
В качестве критерия остановки работы алгоритма обычно выбирают одно из двух условий:
- «центры масс» кластеров стабилизировались, т.е. все наблюдения принадлежат кластеру, которому принадлежали до текущей итерации;
- число итераций равно максимальному числу итераций.
Генерация вектора слов
Для обучения используется популярный набор данных 20 Newsgroups data set [10]. Данные «The 20 Newsgroups» – это коллекция примерно из 20000 новостных документов, разделенная (приблизительно) равномерно между 20 различными категориями. Изначально она собиралась Кеном Ленгом (Ken Lang) для его работы «Newsweeder: Learning to filter netnews» («Новостной обозреватель: учимся фильтровать новости из сети»), хотя он явно не заявлял об этом. Коллекция «The 20 newsgroups» стала популярным набором данных для экспериментов с техниками машинного обучения для текстовых приложений, таких как классификация текста или его кластеризация. Данные разделены на 20 групп, и каждая текстовая группа соответствует разным доменам, таким как sci.med и rec.autos. Для оценки модели используется 11314 обучающих данных. Прежде чем подавать обучающие данные в Word2Vec, необходимо их подготовить. Для работы необходимо обучить нейронную сеть. Набор учебных данных для нейросети word2vec конструируем следующим образом.
1. Очищаем входной текст T от лишних символов (знаки препинания и т.п.).
2. Из очищенного текста T собираем словарь W.
3. Для каждого слова wi∈T собираем контекст, т.е. набор слов Ci⊂T, удалённых от wi не более чем на s позиций в последовательности слов T. Ci = {wj∈T:(i − s) ≤ j ≤ (i + s),j ≠ i} иначе говоря – Ci это слова wj∈T из s-окрестности слова wi∈T.
4. Выполняем унитарное кодирование (one-hot encoding) словаря W, т.е. каждому слову wi∈W ставится в соответствие вектор ui∈U из нулей и одной единицы, длина вектора ui равна размеру словаря W, позиция единицы в векторе ui соответствует номеру слова в словаре W.
5. Заменяем слова в тексте T и контекстах C соответствующими кодами P и Q из U.
Таким образом, получаем два множества – кодированный текст P и наборы кодированных слов контекста Q.
Чтобы хорошо сгенерировать векторы слов, мы используем модель Skip-gram, потому что она обладает лучшей способностью к обучению, чем CBOW, если не учитывать скорость вычислений [6].
На вход модели skip-граммы подается одно слово wi, а на выходе мы получаем слова wi в контексте {wO,1, …, wO,c}, определяемом размером окна слов. После обучения каждому слову соответствует вектор. Наконец, строится матрица большого размера. Каждая строка в матрице представляет каждый пример обучения, а столбцы – сгенерированные векторы слов. Как следствие, слово имеет несколько степеней подобия. Чтобы проверить сходство слов, рассмотрим несколько примеров в табл. 1, в ней приведены два наиболее похожих слова и их косинусные расстояния. Например, с учетом слова «computer» мы получаем два похожих слова «evaluation» и «algorithm» с их расстояниями до «computer». Результаты показывают, что Word2Vec успешно находит семантически связанные слова.
Таблица 1
Сходство слов
|
Слова |
Сходство слов |
|||
|
1-е слово |
Косинусное расстояние |
2-е слово |
Косинусное расстояние |
|
|
computer |
evaluation |
0,9325 |
algorithm |
0,9292 |
|
president |
property |
0,9306 |
population |
0,9123 |
|
american |
Churches |
0,9438 |
Greece |
0,9365 |
Кластеризация слов
Необходимо найти центры каждого кластера слов. В настоящее время некоторые алгоритмы кластеризации могут выполнять эту работу [11]. Учитывая простоту, применяем алгоритм кластеризации K-means. Кластеризация K-means – это метод векторного квантования [12], который разбивает N элементов на K кластеров, минимизируя общую ошибку. Мерой расстояния в данном алгоритме является евклидово расстояние [13]. Единственным параметром, который нужно установить, является количество кластеров K. В табл. 2 показано несколько примеров того, что содержат 4 кластера при K равном 500. Мы можем найти похожие слова, которые почти правильно кластеризованы.
Таблица 2
Содержание кластеров
|
Номер кластера |
Содержимое кластера |
|
1 |
u’my’, u’has’, u’is’, u’in’, u’the’, u’had’, u’for’… |
|
2 |
u’components’, u’speed’, u’trigger’, u’applications’, u’stage’, u’developers’, u’manufacturers … |
|
3 |
u’Medical, u’cigarettes’, u’usma’, u’smoked’, u’food’, u’Laboratory’, u’chewing… |
|
4 |
u’population’, u’federal’, u’laws’, u’treasure’, u’crime, u’organizations’, u’Pope’… |
Многоклассовая классификация
Чтобы оценить производительность модели [14], данные вписываются в многоклассовую классификационную задачу. Во-первых, преобразуем многоклассовую классификацию в несколько двоичных классификаций. Для этого применяется метод One-vs-Rest [13], на выходе которого можно получить единичный классификатор для каждого класса. Экземпляр одного класса рассматривается как положительный класс; Другие считаются отрицательными. Затем применяется LinearSVC (Linear Support Vector Classifier), на вход которой подаются результаты всех единичных классификаторов, а на выходе определенный моделью класс.
Производительность
Чтобы оценить эффективность классификации, вычисляется показатель F1-micro [15] и фиксируется время работы. В табл. 3 показана эффективность классификации для наборов данных с уменьшением размеров. В первой строке показано значение F1-micro и время, затрачиваемое без применения Word2Vec и алгоритма кластеризации. Остальные строки представляют производительность классификации данных с уменьшением размеров. Из полученных данных очевидно, что чем исходный набор данных больше, тем результаты лучше.
Таблица 3
Производительность классификации
|
Размер данных |
Производительность классификации |
|
|
F1-Micro |
Время (s) |
|
|
11,314 * 61,189 |
0,7524 |
5 * 10^3 |
|
11,314 * 2000 |
0,774 |
8 *10^2 |
|
11,314 * 1500 |
0,7619 |
6 * 10^2 |
|
11,314 * 1000 |
0,753 |
4 * 10^2 |
|
11,314 * 500 |
0,7506 |
3 * 10^2 |
Выводы
В работе рассмотрен пример применения Word2Vec к обработке больших данных. Вначале обучающие данные подаются на вход в Word2Vec для генерации векторов слов. Для каждого слова рассчитывается вектор, с помощью которого находятся семантически связанные слова. Далее подобные слова группируются, используя алгоритм кластеризации K-means. Задавая значение K, определяется количество кластеров. Был проведен ряд экспериментов с целью определения эффективности предложенной модели. Исходя из результатов проведенных экспериментов, можно судить о достаточно высокой производительности данной модели. Также из экспериментов видно, что чем больше объем исходных данных, тем точность алгоритма выше.
Библиографическая ссылка
Черепков Е.А., Глебов С.А. ИСПОЛЬЗОВАНИЕ МОДЕЛИ WORD2VEC ДЛЯ КЛАСТЕРИЗАЦИИ БОЛЬШИХ ТЕКСТОВЫХ ДАННЫХ // Научное обозрение. Технические науки. 2017. № 3. С. 21-24;URL: https://science-engineering.ru/ru/article/view?id=1170 (дата обращения: 23.06.2026).