

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
WATER SOURCES FORMATION FOR THE WATERSHED ALGORITHM BASED ON A SEARCH OF KEYPOINTS

Оперативная обработка изображений с целью определения геометрических характеристик формы хаотично расположенных материалов является актуальной проблемой. Область применения таких систем чрезвычайно широка [1–12]. Сложность решения данной задачи связана с произвольным расположением материалов в несколько слоев, их частичным перекрытием, например, при движении материалов в потоке на конвейерной ленте.
Существуют два принципиально разных подхода к решению данной проблемы. Первый подход – геометрический. Он предполагает поиск контуров кусков материалов, по которым далее решается задача оценки параметров формы. Альтернативный подход – статистический. Он основан на поиске набора определяющих параметров, расчет которых осуществляется на базе совокупности моментов частей исходного изображения. Оба подхода имеют свои достоинства и недостатки, подробно рассмотренные в работах многих авторов. Основной проблемой геометрического подхода является перекрытие отдельных кусков материалов другими, а также наличие слабо выраженных границ между областями разных кусков на изображении. Данная работа направлена на совершенствование геометрического подхода путем разработки более совершенных алгоритмов сегментации изображения, основанных на алгоритме водораздела.
Сегментация изображения на основе алгоритма водораздела
В работе [6] был предложен алгоритм обработки изображения для оценки лещадности щебня, представленный на рисунке 1. Лещадность – процент содержания зерен, у которых соотношение наибольшего линейного размера к наименьшему более чем 3:1 [13].
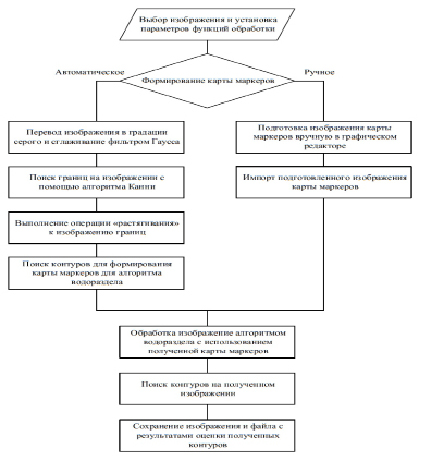
Рис. 1. Алгоритм автоматической обработки изображения
Одной из его проблем является сложность формирования карты маркеров на исходном изображении. При использовании ручной расстановки маркеров алгоритм выдает приемлемые результаты, что видно на рис. 2, б. Однако при использовании автоматической расстановки маркеров с помощью детектора границ Канни и операции «расстягивания» эффективность работы алгоритма снижается, рис. 2, в.
Возможным способом совершенствования алгоритма может послужить формирование карты маркеров на основе поиска объекта по дескрипторам ключевых точек. Для получения таких дескрипторов требуется предварительная обработка изображений, на которых присутствует выходной продукт. Затем на изображении с камеры также происходит поиск дескрипторов, их кластеризация и построение карты маркеров.
а б в

Рис. 2. Обработка исходного изображения по алгоритму: а – исходное изображение; б – результат выполнения алгоритма с формированием карты маркеров вручную; в – результат выполнения алгоритма с автоматическим формированием карты маркеров
Разработка способа формирования ключевых точек
Способ основывается на вычислении ключевых точек на исходных обучающих изображениях и выделении фрагментов этих изображений с целью получения перцептивного хеша. Далее ключевые точки ищутся на новых изображениях, выполняется их кластеризация, и ищутся соответствия хеша с эталонами. При достаточной степени совпадения считаем, что кластер описывает отдельный кусок материала. Далее выполняем поиск центров кластеров и формируем карту маркеров.
Такой метод поиска объекта имеет следующие недостатки: низкая скорость проверки на совпадение на большом наборе хешей (поиск по 1 млн хешей занимает больше 30 с); низкая скорость получения ключевых точек.
Для устранения этих недостатков использовали алгоритм HEngine для поиска хешей по базе с расстояния Хэмминга меньше 10. Это позволяет примерно в 60 раз ускорить поиск нужных данных, но также требует перевода хешей в бинарный вид.
Так как предполагается работа с бинарными хешами, а совпадение считаем расстоянием Хэмминга, то SURF дескрипторы не подходят. В OpenCV есть два типа дескрипторов: с плавающей точкой (SURF) и бинарные (ORB). Использовали второй вариант (ORB), который представляет улучшенную версию и комбинацию детектора ключевых точек FAST и бинарных дескрипторов BRIEF. Также он работает быстрее SURF метода. Однако ORB имеет недостаток, связанный с тем, что дескриптор использует для хранения одной точки тридцать два байта памяти, а в задаче подразумевается, что одна точка имеет восемь байт информации. Требуется сжатие тридцати двух байт в восемь, при незначительных потерях в качестве.
Для решения проблемы использовали алгоритм pHash. 32 байта представим в виде матрицы 16?16 бит, а потом пропустим ее через перцептивный хеш pHash, получая в результате число размеров восемь байт.
Шаги работы алгоритма: 1) Получаем ключевые точки и дескрипторы ORB, выбираем количество требуемых точек на изображении; 2) Полученные дескрипторы по 32 байта представляем в виде битовой матрицы 16?16. 3) Конвертируем матрицу в 64-битное число с помощью PHash; 4) Сохраняем 64-битные отпечатки в файл в JSON формате или используем базу данных; 5) Выбираем требуемое расстояние Хэмминга и запускаем HEngine, который будет выполнять поиск; 6) Выполняем 1–3 шаги для изображения с камеры; 7) Запускаем HEngine, который возвращает все хеши в заданном пределе; 8) Выполняем кластеризацию и формируем карту маркеров на изображении.
Пример результата выделения ключевых точек и поиска объекта можно видеть на рис. 3. Серые маркеры показывают найденные ключевые точки, зеленые – совпадающие точки, красные – совпадающие стандартным методом ORB полным перебором.
а

б

Рис. 3. Пример поиска объекта по дескрипторам: а – исходное изображение; б – поиск признаков на общем изображении с выделением кластеров и формированием карты маркеров
Заключение
Таким образом, использование дескрипторов ключевых точек может повысить точность автоматического формирования карты маркеров, но для его реализации требуются изображения искомого продукта. Также данный метод использует большое количество операций, что негативно сказывается на быстродействии алгоритма.
Библиографическая ссылка
Бурнашев Р.Э., Берестов А.П., Рябчиков М.Ю. ФОРМИРОВАНИЕ КАРТЫ МАРКЕРОВ ДЛЯ АЛГОРИТМА ВОДОРАЗДЕЛА НА ОСНОВЕ ПОИСКА КЛЮЧЕВЫХ ТОЧЕК // Научное обозрение. Технические науки. 2017. № 1. С. 5-9;URL: https://science-engineering.ru/en/article/view?id=1140 (дата обращения: 02.08.2026).