

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
PASSIVE TECHNOLOGIES OF HUMAN HEAD MODELING

Распознавание лица на неподвижном изображении – важная задача и часто она является первым шагом в алгоритмах приложений для реализации взаимодействия человек–компьютер. Целью таких алгоритмов является определение отсутствия или присутствия лица на произвольном изображении и, если оно есть, то необходимо выявить его положение и размер [3].
Технологии 3D-моделирования лица можно разделить на два класса – активные и пассивные – в зависимости от методов обработки изображений и методов дальнейшей реконструкции 3D-модели.
Существующие на данный момент активные системы 3D-распознавания лиц используют специальное оборудование для реконструкции трехмерной модели лица (сенсорные системы) [1]. Существует зависимость между ценой и точностью системы.
Большинство высокоточных систем стоят десятки тысяч долларов и требуют высокой квалификации персонала, как для настройки, так и для использования. Но высокие темпы развития компьютерных технологий и технологий обработки видео привели к созданию относительно недорогих систем, которые можно применять в большинстве областей [2].
Методы пассивного моделирования используют несколько изображений, которые были захвачены без датчиков. Для пассивной реконструкции необходимо одно изображение, либо совокупность нескольких изображений, захваченных одновременно, а также может использоваться последовательность изображений, то есть видео. Одни из самых распространенных методов пассивного моделирования включают в себя стереозрение, морфинг и определение формы по перемещению.
Стереозрение. Для метода стереозрения характерны две камеры, которые работают синхронно. С их помощью можно восстановить изгиб и местоположение наблюдаемого объекта в системе координат сцены. Главная задача данной технологии – получить две необходимые карты. Одна из них называется карта глубины – это такое изображение, где для каждого пиксела хранится не только информация о цвете, но и также содержится информация о том, как далеко объект расположен от камеры. Другая карта называется карта глубины, она создается с помощью стереопары изображений. Принцип ее создания прост: для всех точек на одной фотографии находятся парные им точки на другой фотографии. Точно также для всех пикселей первого изображения находятся парные пиксели на втором изображении. Предположим, что координаты пикселя на первом изображении равны (x0 – d, y0), где d – параметр, который называется несоответствием или смещением. Чем больше несоответствие, тем меньше глубина. Если соответствие между точками сцены стереоизображений установлено максимально правильно, то стереосистемы смогут восстановить высокоточную глубину. Рис. 1(a) иллюстрирует бинокулярную стереоустановку с двумя идентичными камерами, сфокусированными на одной и той же сцене.
Точка P1 (X, Y, Z) находится на расстояниях xl и xr от точки фокусировки соответственно левого и правого изображений. Несоответствие |xl – xr| для P1 меньше, чем для точки P2, расположенной относительно ближе к камерам. Для установки связи между 2D-координатами точек изображения (x, y) и 3D-координатами (X, Y, Z) сцены требуется ряд параметров. В процессе калибровки оцениваются два типа параметров: (1) внешние, связанные с относительным положением камер и (2) внутренние, связанные с самой камерой. Внутренними параметрами являются характеристики камеры, такие как фокусное расстояние f, длина пикселя sx, ширина sy и координаты главной точки (Ox, Oy). Внешними параметрами являются три поворота и три перевода камеры относительно мировой системы координат.
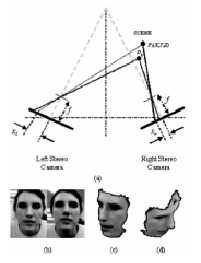
Рис. 1. 3D-реконструкция головы человека методом стереозрения: a – бинокулярная система стереозрения, b – стереопара, c-d – реконструированная часть трехмерной модели
Пренебрегая радиальным искажением объектива, внешние и внутренние параметры могут быть представлены двумя матрицами преобразования Mext и Mint. Предполагая, что Ox = Oy = 0 и sx = sy =1, единственная матрица преобразования M может быть записана как [8]
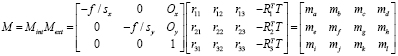 . (1)
. (1)
Здесь rij – элементы R – вращение мировых координат относительно координат камеры, Ri – i-й вектор столбца R; T – вектор сдвига из начала мировой системы координат.
В гомогенной системе координат получаем линейное матричное уравнение, описывающее перспективную проекцию как:
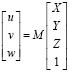 . (2)
. (2)
Координаты изображения определяются как x = u / w и y = v / w. Мы можем разделить обе части (2) на ml и уменьшить число параметров до 11. Если (xl, yl) – точка на изображении, снятом левой камерой, можно записать
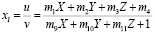 ; (3)
; (3)
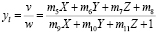 ; (4)
; (4)
В наши дни мощности процессоров и видеокарт постоянно увеличиваются, однако существующие алгоритмы стереозрения значительно медлительны.
Морфинг с использованием обобщенной модели. Морфинг требует, чтобы обобщенная форма объекта была априори известна. Общая форма лица человека может быть получена с помощью лазерных сканеров или структурированных световых систем путем захвата нескольких моделей, а затем их усреднения. Общая модель 3D-головы может быть изменена (т.е. деформирована) для того, чтобы получить конкретную трехмерную модель определенного человека.
Процесс морфинга (т.е. деформации общей 3D-модели) состоит в том, что 2D-проекции 3D-модели должны максимально приближаться к одному или нескольким оригинальным изображениям лица (рис. 2) [7].
Алгоритм морфинга не вызывает сложностей. Если нам известна величина смещений и весовых коэффициентов базовых точек, необходимо изменить значения местоположений в пространстве этих точек. Каждое значение точек необходимо увеличить на число, которое вычисляется, как произведение ее смещения и веса. Алгоритм можно объяснить следующим уравнением:

Рис. 2. Иллюстрация лицевой реконструкции методом морфинга: a – лицевая часть 3D-шаблона; b – трехмерный шаблон, наложенный на двумерное изображение лица; c – промежуточная стадия морфинга 3D-шаблона; d – реконструированная трехмерная модель лица
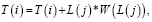 (5)
(5)
здесь в T хранится информация о местоположении точек в пространстве, i = 0, 1315; j = 0; L(j) – смещение для j-й базовой точки, а W(L(j)) –значение веса i-й точки, связанной с j-й базовой точкой.Уравнение для алгоритма морфинга, записанное для всех точек изображения в анфас:
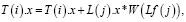 (6)
(6)
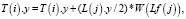 (7)
(7)
Уравнение для алгоритма морфинга, записанное для всех точек изображения в профиль:
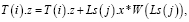 (8)
(8)
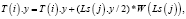 (9)
(9)
Морфинг является довольно дорогостоящим из-за его итеративного характера. В некоторых случаях требуется ручная подгонка при выравнивании общей 3D-модели. Эти ограничения делают невозможным использование морфинга в приложениях, работающих в режиме реального времени. Тем не менее, морфинг способен восстанавливать трехмерную часть головы человека, используя всего одно 2D-изображение [5].
Определение формы по перемещению. Shape-from-motion, или 3D-реконструкция по видео, создает 3D-модель объекта из видеопоследовательности. Видео должно иметь по крайней мере два кадра и небольшие различия между точками в последовательных кадрах. В видеороликах с большими различиями между кадрами объект может быть восстановлен с использованием стереозрения, когда известны внутренние параметры камеры [8].
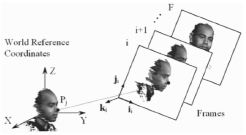
Рис. 3. Иллюстрация трехмерной реконструкции лица из видео. N – число характерных точек, которые отслеживается по F числу кадров, где Pj (j = 1, ..., N)
Глубина по видео может быть восстановлена с использованием одного из двух основных подходов – либо путем отслеживания характерных особенностей, либо вычисления оптического потока. Подход по отслеживанию характеристик требует одновременного согласования токенов в нескольких выбранных точках. Оптический поток наоборот может быть рассчитан либо абсолютно точно в каждой точке, либо ограниченно в нескольких точках объекта из пространственных и временных производных яркости изображения.
3D-реконструкция по видео широко используется в ряде приложений, таких как surveillance [3]. Тем не менее, данный метод имеет свой недостаток – такое моделирование довольно сильно зависит от наличия шумов на видео, и это может привести к дальнейшей некачественной реконструкции [4, 6].
В настоящее время активные методы более распространены, чем пассивные, однако они имеют существенный недостаток – с помощью активных методов невозможно восстановить трехмерную структуру из 2D-изображений головы человека. Поэтому, в случае, когда 2D-изображения являются единственными доступными данными, пассивные методы реконструкции 3D-модели могут сыграть ключевую роль.
Библиографическая ссылка
Бацева Д.А., Белов Ю.С. ПАССИВНЫЕ ТЕХНОЛОГИИ МОДЕЛИРОВАНИЯ ГОЛОВЫ ЧЕЛОВЕКА // Научное обозрение. Технические науки. 2017. № 2. С. 11-14;URL: https://science-engineering.ru/en/article/view?id=1155 (дата обращения: 12.07.2026).