

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
BASIC IMAGE PROCESSING TECHNIQUES IN OFFLINE HANDWRITING RECOGNITION

Оффлайн-распознавание рукописного текста обычно состоит из следующих этапов: предварительная обработка изображения, сегментация и нормализация, извлечение признаков, классификация и обработка результатов.
На этапе предварительной обработки изображения используются методы обработки изображений (фильтрация, шумоподавление и другие), и имеющие своей целью повысить качество изображения.
На данный момент задача распознавания рукописного текста является нерешенной. Задача повышения качества изображения при распознавании рукописного текста является достаточно актуальной, поскольку чем лучше будет качество изображения, тем удобнее будет работать с ним на последующих этапах распознавания [1] и, соответственно, качество распознавания также будет лучше.
Улучшение качества изображения включает обычно в себя преобразование изображения в градации серого, удаление дефектов изображения и отделение текста от фона.
Преобразование изображения
в градации серого
Обычно для упрощения дальнейшей работы с изображением делается преобразование изображения в градации серого [2].
Для каждого отдельного пикселя вычисляется значение яркости, которое измеряется в диапазоне от 0 до 255. Черный цвет соответствует 0 уровню яркости, а белый – 255 уровню. Это вычисление производится при помощи следующей формулы:
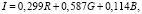
где R, G, B – значения красного, зеленого и синего каналов соответственно.
Удаление дефектов
Удаление дефектов осуществляется стандартными методами обработки изображений. Наиболее часто для удаления шума используют фильтр Гаусса для подавления высокочастотного шума [3] и медианный фильтр для удаления шума «соль и перец» (рис. 1). Также перспективным фильтром является фильтр на основе вейвлет-преобразования [4].
Фильтр Гаусса
Данный фильтр основан на функциях Гаусса одной и двух переменных соответственно:
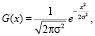
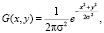
где σ – «степень размытия» обработанного изображения (стандартное отклонение нормального распределения); x, y – расстояние между пикселем (исходной точкой) и точкой, для которой подсчитывается значение функции Гаусса по вертикальной и горизонтальной оси соответственно [5].
Следовательно, при помощи функции Гаусса можно построить матрицу свертки, которая помогает для каждого пикселя изображения рассчитать средневзвешенное значение соседних пикселей:
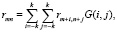
где k – размерность матрицы свертки.
Таким образом, посредством применения фильтра Гаусса шум будет подавлен, поскольку все зашумленные пиксели (яркость которых сильно отличается от яркости соседних пикселей) примут усредненное значение, в результате чего контуры объектов будут подчеркнуты, что положительно повлияет на результат распознавания образов (в том числе и рукописного текста) на цифровых изображениях.
Медианный фильтр
Понятие медианы лежит в основе медианного фильтра. Если множество A, состоящее из чисел Ai, где i = 1..n, отсортировано по возрастанию, то An/2 – является медианой этого множества [6]. Медиана будет делить отсортированный набор чисел на две части, где первая часть будет содержать числа, которые меньше, чем медиана, а вторая часть – больше.


а) б)
Рис. 1. Примеры распространенных типов шумов: а) шум «соль и перец»,
б) высокочастотный шум
Распространенный способ реализации данного фильтра заключается в том, чтобы отсортировать значения яркостей пикселей при помощи окна [7] с нечетным радиусом и затем заменить значения яркостей пикселей на значение медианы результирующего множества.
Фильтр на основе вейвлет-преобразования
Так как изображение можно представить в виде дискретного сигнала, то для его обработки можно использовать фильтры, базирующиеся на частотном разделении в дискретной области. Вейвлет-анализ является достаточно перспективным способом анализа данных.
Сигнал можно представить следующим образом:
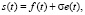
где f(t) – полезный сигнал, e(t) – шум, σ – уровень шума, s(t) – исследуемый сигнал.
Таким образом, вейвлет-преобразование позволяет удалить шум за 4 шага [8, 9]:
– разложение сигнала по базису вейвлетов;
– выбор порогового значения шума для каждого из уровней разложения;
– пороговая фильтрация коэффициентов детализации;
– восстановление сигнала.
Такой способ фильтрации лучше всего работает на гладких сигналах, т.е. на таких сигналах, в разложении которых лишь небольшое количество коэффициентов детализации значительно отличается от нуля.
Подбор вейвлета и глубины разложения обычно зависит от свойств фильтруемого сигнала.
Для выбора порога шума обычно используют критерии, которые минимизируют квадратичную функцию потерь для выбранной модели шума.
Данные фильтры реже используются по сравнению с медианными, потому что использование вейвлетов приводит к дополнительной параметризации программы и замедлению работы, поскольку требуется вычисление дополнительных массивов данных.
Отделение текста от фона
Отделение текста от фона является частным случаем задачи выделения объекта на изображении. Задача состоит в том, чтобы по изображению текста A построить бинарное изображение B, такое, что
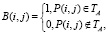
где P(i, j) – пиксель (i, j), TA – текст на изображении А.
Данное преобразование позволяет в дальнейшем использовать анализ связных компонент, контуров, скелетов и т.д.
Наиболее часто использующимся методом отделения текста от фона служит пороговая бинаризация (threshold binarization). Пусть дано изображение, I(i, j) – яркость пикселя с координатами (i, j). Пороговой бинаризацией изображения называется попиксельное преобразование f(i, j), такое, что
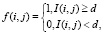
где d называется порогом бинаризации.
Обычно на гистограмме яркости изображения текста наблюдается два пика: высокий пик в области светлых пикселей, который соответствует фону, и более низкий пик в области тёмных, который соответствует тексту. Таким образом, задача поиска порогового значения яркости, т.е. такого, чтобы пиксели с яркостью выше этого значения (фон) будут считаться чёрными, а ниже (текст) – белыми (такое «инвертирование» цвета делается в целях упрощения применения многих алгоритмов в дальнейшем), является задачей поиска оптимального значения между двумя пиками гистограммы. Для решения этой задачи существуют хорошо изученный метод Оцу и его вариации.
Метод Оцу
В данном методе диапазон яркостей
[0; L] изображения делится на две части пороговым значением T. Суть алгоритма состоит в том, чтобы минимизировать внутриклассовую дисперсию, которая определяется как взвешенная сумма дисперсий двух классов. В алгоритме Оцу минимизация внутриклассовой дисперсии эквивалентна максимизации межклассовой дисперсии, которая рассчитывается следующим образом:
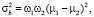
где σb – межклассовая дисперсия, w1 и w2 – вероятности первого и второго классов, μ1 и μ2 – средние арифметические значения каждого из классов. Каждая из перечисленных величин рассчитывается следующим образом:
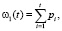
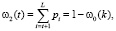
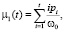
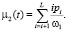
Схема алгоритма описывается следующим образом:
– Рассчитывается гистограмма на основе значений pi = ni / N, где N – суммарное количество пикселей изображения, ni – количество пикселей с яркостью i.
– Со значения порога t = 1 делается проход по всей гистограмме, пересчитывая на каждом шаге дисперсию σb(t). Если на каком-либо шаге дисперсия стала больше максимума, то обновляется максимум дисперсии и назначается новое текущее значение T = t.
– T – результирующее пороговое значение.
Недостатком данного метода является чувствительность к неравномерной освещенности. Для решения данной проблемы обычно получают компонент освещения путем низкочастотной фильтрации G изображения при помощи фильтра Гаусса [10].
Метод адаптивной бинаризации
Еще одним недостатком метода Оцу является слипание близко расположенных областей, что может повлиять на дальнейшую обработку и распознавание. Поэтому существует метод адаптивной бинаризации, который к тому же позволяет решить проблему разности освещенности.

Рис. 2. Результат пороговой бинаризации
Для окрестности R пикселя вычисляется порог T. Порог Т может являться средним значением яркости по области R, медианой выборки из области R или вычисляться по формуле: (Imax – Imin) / 2. Значение пикселя B(x, y) в бинарном изображении вычисляется следующим образом:
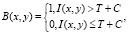
где I(x, y) – яркость пикселя в исходном изображении, С – произвольная константа.
Результатом бинаризации изображения является бинарное изображение белого текста на чёрном фоне, соответствующего исходному изображению (рис. 2).
Таким образом, были рассмотрены основные методы обработки изображений при оффлайн распознавании рукописного текста. Следует грамотно подходить к выбору методов обработки изображения, поскольку при правильном выборе они являются залогом успешного распознавания текста.
Библиографическая ссылка
Басанько А.С., Белов Ю.С. ОСНОВНЫЕ МЕТОДЫ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ПРИ ОФФЛАЙН-РАСПОЗНАВАНИИ РУКОПИСНОГО ТЕКСТА // Научное обозрение. Технические науки. 2018. № 3. С. 5-8;URL: https://science-engineering.ru/en/article/view?id=1184 (дата обращения: 26.07.2026).