

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
QUALITY ASSESSMENT APPROACH OF MACHINE TRANSLATION BASED ON PHRASES ALIGNMENT

Этап выравнивания является важной частью машинного перевода, который заключается в определении соответствия между словами/фразами имеющими одинаковое значение на одном языке со словами/фразами на другом языке. Результатом выравнивания является параллельный текст, который используется для инициализации систем машинного перевода [1]. Улучшение выравнивания позволяет увеличить точность создаваемого системой перевода и кроме того способно внести значительный вклад при оценке качества такого перевода. Целью исследования является разработка подхода к оценке качества машинного перевода с использованием фразового выравнивания.
Механизм выравнивания на основе слов
Рассмотрим механизм выравнивания на примере [2]. Одним из способов визуализации задачи выравнивания является матрица (рис. 1).
Здесь соответствующие выравнивания между словами представлены точками в матрице выравнивания. Выравнивания слов не обязательно должны иметь однозначное соответствие. Слова могут иметь несколько точек выравнивания или не иметь их вовсе. Так, на рис. 1 английское слово assumes соответствует трем немецким словам geht davon aus. Однако не всегда легко установить корректное выравнивание слов. Основная проблема заключается в том, что некоторые слова не имеют четкого эквивалента на другом языке.
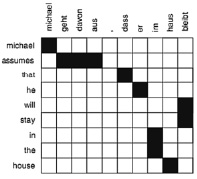
Рис. 1. Пример матрицы выравнивания слов: Слова на английском языке (строки) выровнены по словами на немецком языке (столбцы), как указано точками в матрице
Для учета выравнивания по нескольким словам можно применить модель выравнивания в двух направлениях: от источника к цели и от цели к источнику. Полученные в результате выравнивания слова могут быть объединены, например, путем объединения точек пересечения или объединения всех точек выравнивания. Этот процесс обычно называют симметризацией выравнивания [2].
Механизм выравнивания на основе фраз
Как уже было указано ранее, иногда одно слово на исходном языке переводится как два или более слова на целевом языке. Процесс симметризации не всегда помогает исправить подобную ситуацию [3]. Один из вариантов решения данной проблемы – использовать более крупные единицы перевода, например фразы. Процесс выравнивания на основе фраз включает в себя два шага:
– создание выравнивания на основе слов между каждой парой предложений параллельного корпуса;
– извлечение фразовых пар, которые соответствуют полученному выравниванию слов.
Для рассматриваемого примера пошаговый процесс извлечения выровненных фраз отражен в таблице.
Процесс извлечения выровненных фраз
|
Этап |
Фраза на английском языке |
Фраза на немецком языке |
|
1 |
michael |
michael |
|
2 |
michael assumes |
michael geht davon aus; michael geht davon aus, |
|
3 |
michael assumes that |
michael geht davon aus, dass |
|
4 |
michael assumes that he |
michael geht davon aus, dass er |
|
5 |
michael assumes that he will stay in the house |
michael geht davon aus, dass er im haus bleibt |
|
6 |
assumes |
geht davon aus; geht davon aus, |
|
7 |
assumes that |
geht davon aus, dass |
|
8 |
assumes that he |
geht davon aus, dass er |
|
9 |
assumes that he will stay in the house |
geht davon aus, dass er im haus bleibt |
|
10 |
that |
dass ; , dass |
|
11 |
that he |
dass er ; , dass er |
|
12 |
that he will stay in the house |
dass er im haus bleibt ; , dass er im haus bleibt |
|
13 |
he |
er |
|
14 |
he will stay in the house |
er im haus bleibt |
|
15 |
will stay |
bleibt |
|
16 |
will stay in the house |
im haus bleibt |
|
17 |
in the |
im |
|
18 |
in the house |
im haus |
|
19 |
house |
haus |
Оценка выравнивания для каждой пары фраз  строится поверх оценок выравнивания слов следующим образом:
строится поверх оценок выравнивания слов следующим образом:
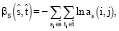 (1)
(1)
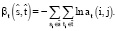 (2)
(2)
Функция внешнего выравнивания
Выравнивание подразумевает не только то, что слова в пределах исходной фразы выровнены со словами в пределах целевой фразы, но также что оставшаяся часть исходного предложения, выровнена с подобной частью целевого предложения. Предположим, что набор фраз в исходном предложении – S, в целевом – T. Функция внешнего выравнивания будет выглядеть следующим образом:
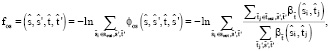 (3)
(3)
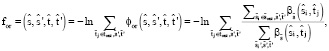 (4)
(4)
sout и tout – набор фраз за пределами соответствия между 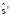 и
и 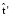 .
.
Функция покрытия
Кроме того, полезно учесть, какую часть переводимого текста покрывает рассматриваемая фраза. Пусть 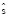 и
и 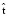 представляют исходную и целевую фразы, S и T представляют исходное и целевое предложения. Отношения
представляют исходную и целевую фразы, S и T представляют исходное и целевое предложения. Отношения  и
и 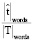 отражают покрытие текста каждой выровненной фразой (1 – предложение охвачено полностью, 0 – отсутствие покрытия). Соответствующие функции выглядят следующим образом:
отражают покрытие текста каждой выровненной фразой (1 – предложение охвачено полностью, 0 – отсутствие покрытия). Соответствующие функции выглядят следующим образом:
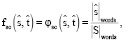 (5)
(5)
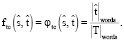 (6)
(6)
Корреляция между частотами исходных и целевых фраз
С целью сохранить количество предложений в корпусе, в которых встречается конкретная выровненная фраза, вводится дополнительная функция. Пусть 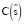 – число вхождений фразы
– число вхождений фразы 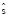 в корпус. Аналогичным образом,
в корпус. Аналогичным образом, 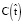 – число вхождений фразы
– число вхождений фразы 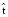 в корпус. Функция частот будет выглядеть следующим образом:
в корпус. Функция частот будет выглядеть следующим образом:
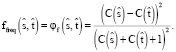 (7)
(7)
Функция итоговой оценки
Учитывая пару фраз 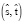 и выровненное соответствие
и выровненное соответствие 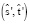 , определяется функция
, определяется функция 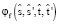 для обеспечения единого представления функций, описанных ранее:
для обеспечения единого представления функций, описанных ранее:
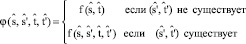 (8)
(8)
Используем метод аппроксимации логарифмической модели для оценки единиц машинного перевода [4]. Общая функция оценки 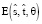 для пары фраз
для пары фраз 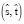 будет выглядеть следующим образом:
будет выглядеть следующим образом:
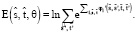 (9)
(9)
Результаты работы метода
Для оценки предложенного подхода использовался набор данных WMT 2013. Данные сопровождаются широким спектром языковых пар. В данной работе рассматривались две пары параллельных корпусов: французско-английский и испанско-английский. Параллельные корпуса сопровождаются ручными и автоматическими оценками перевода [5]. Для оценки эффективности данного подхода результаты сравнивались с традиционными метриками оценки МП, такими как BLEU [6], GTM, TER и METEOR [7].
Для определения корреляции с человеческими суждениями использовался коэффициент корреляции баллов Спирмана.
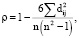 (10)
(10)
где dij – евклидово расстояние, вычисляемое как разница между данной метрикой оценки и оценкой суждения человека, n – число переводов.
В предлагаемом подходе необходимо было выбрать наиболее подходящую размерность N-грамм. N-грамма состоит из N последовательных слов для каждой фразы выравнивания. Рис. 2, 3 демонстрируют влияние выбора различных значений N на точность предложенного подхода.
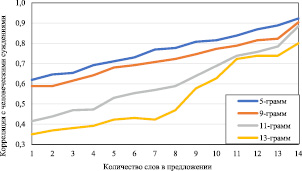
Рис. 2. Влияние разной длины N-грамм на корреляцию с суждениями человека с использованием французско-английских данных WMT 2013
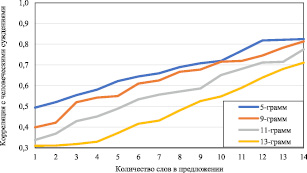
Рис. 3. Влияние разной длины N-грамм на корреляцию с суждениями человека с использованием испанско-английских данных WMT 2013
Было обнаружено, что уменьшение значения N приводит к устойчивому улучшению корреляции с человеческими суждениями. В связи с этим было решено проводить дальнейшее тестирование с N-граммами в размере 5 и 9 слов.
На рис. 4, 5 представлена сводная информация о результатах корреляции предлагаемого подхода в сравнении с другими метриками.
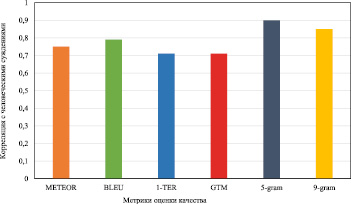
Рис. 4. Сравнение с использованием французско-английских данных WMT 2013
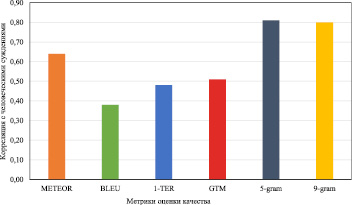
Рис. 5. Сравнение с использованием испанско-английских данных WMT 2013
Результаты показали, что предлагаемый подход имеет наилучшую производительность на тестируемом наборе данных. Предложенный подход обеспечивает повышение точности не менее чем на 3,85 %.
Заключение
Таким образом, разработанный в данной работе подход показывает лучшие результаты в сравнении с традиционными метриками машинного перевода. Данный подход имеет потенциал, может быть в дальнейшем улучшен, например, введением дополнительных вероятностных функций с учетом различных границ выравнивания, а также с включением человеческих оценок в процесс обучения системы.
Библиографическая ссылка
Козина А.В., Черепков Е.А., Белов Ю.С. МЕТОД ОЦЕНКИ КАЧЕСТВА МАШИННОГО ПЕРЕВОДА НА ОСНОВЕ ФРАЗОВОГО ВЫРАВНИВАНИЯ // Научное обозрение. Технические науки. 2019. № 6. С. 50-55;URL: https://science-engineering.ru/en/article/view?id=1270 (дата обращения: 02.08.2026).