

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
SELECTION OF VALUES OF PARAMETERS OF THE DESIGNED RECOMMENDED SYSTEM BASED ON ANALYSIS OF THE BEHAVIOR OF USERS ON THE NETWORK

Поведение пользователя достаточно абстрактная вещь, поэтому ни одна из метрик не сможет в полной мере описать мыслительные процедуры, происходящие в голове человека в процессе выбора. Но реализация работы рекомендательной системы пытается максимально точно проанализировать поведение человека, предшествующее отданию предпочтения тому или иному продукту.
Задача рекомендательной системы – проинформировать пользователя о товаре, который ему может быть наиболее интересен в данный момент времени. Клиент получает информацию, а сервис зарабатывает на предоставлении качественных требуемых услуг.
В рамках данного подхода рекомендации генерируются на основании интересов других похожих пользователей и непосредственно поведения человека, которому будет сделано предсказание.
Цель исследования: рассмотреть процесс подбора параметров рекомендательной системы. А затем проанализировать изменения качества и точности получаемых предсказаний.
Объект исследования: рекомендательные системы – это алгоритмы, которые способны распознавать такие закономерности, о существовании которых люди могут даже не подозревать.
Входные данные. В данной работе в качестве входных данных была использована база данных электронной торговли «events», ее часть представлена в таблице. Для сжатия входных данных и выделения в них зависимостей используется обработчик. Он позволяет облегчить процедуру обучения и улучшить качество прогнозирования [1–3].
Часть базы данных «events»
|
timestamp |
visitorid |
event |
itemid |
transactionid |
|
1433221332117 |
257597 |
view |
355908 |
|
|
1433224214164 |
992329 |
view |
248676 |
|
|
1433221999827 |
111016 |
view |
318965 |
|
|
1433222276276 |
599528 |
transaction |
356475 |
4000 |
Где в колонке timestamp отмечено время, а именно метка времени «юникс» – это вариант кодировки времени. Время было конвертировано таким образом для удобства работы с данным параметром. Так как юникс-время занимает меньше места, следовательно, легче обрабатывать базу в целом. К тому же его можно легко конвертировать в привычную дату.
Следующий столбец visitorid, или идентификатор пользователя – это уникальное значение каждого пользователя, которое присваивается ему в момент посещения сайта.
Далее идет столбец event, или событие – все действия пользователя можно разбить на три категории, а именно view – просмотр, addtocart – добавление в корзину и transaction – непосредственно покупка.
Столбец itemid, или идентификатор товара – это уникальный идентификатор каждого товара.
И заключительный столбец transactionid, или идентификатор покупки – это уникальное значение, присваиваемое каждой покупке.
Для наглядности рассмотрим последнюю строку таблицы. Она сообщает о том, что посетитель 599528 приобрел товар 356475, идентификатор данного события 4000, временная метка данного события 1433222276276.
Ошибка обучения. В качестве функции для вычисления ошибки обучения модели была выбрана функция кросс-энтропии, или логарифмическая функция потерь. Для вычисления ошибки обучения была выбрана данная функция, так как она позволяет измерить разницу между полученными и целевыми результатами [4; 5].
Если значение функции кросс-энтропии маленькое, следовательно, предсказание достаточно точное, если большое, то нет со- ответственно.
В случае большой величины функции ошибки необходимо ее уменьшить, для этого применяется инструмент для обновления весов нейронов optimizer с использованием метода Адам. И выполняется своеобразное обратное распространение ошибки обучения в сочетании с градиентным спуском с «импульсом» [6–8].
Предпочтение данному методу было отдано в связи с тем, что стандартный инструмент обратного распространения ошибки обучения имеет значительный недостаток при попадании в локальные минимумы, что приводит к ошибочным результатам в работе метода.
В основе метода Адам, как уже было сказано выше, заложена концепция «импульса или момента», за счет прибавления предыдущих градиентов к текущим, при слабом обновлении весов для типичных признаков и при небольшой скорости обучения [9; 10].
Результаты работы системы. Таким образом, после выполнения всех этапов обработки спроектированная система показывает результаты, представленные на рис. 1. Данный рисунок отражает предсказание, данное системой, то есть конкретные itemid, пользователю visitorid = 56. Для определения их достоверности было выполнено сравнение полученных предсказаний с целевыми данными.
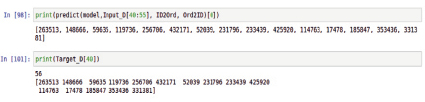
Рис. 1. Сравнение полученных предсказаний с целевыми данными
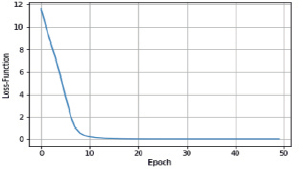
Рис. 2. Изменения ошибки обучения для первой модели

Рис. 3. Значения изменения ошибки обучения и точности предсказания для первой модели
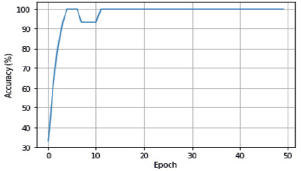
Рис. 4. График изменения точности предсказания для первой модели
Подбор параметров системы. Для подтверждения оптимальности архитектуры разработанной системы были проведены серии экспериментов, в которых изменялись ее параметры. В качестве параметров системы были выбраны следующие:
– количество нейронов в скрытом слое «hidden_dim»;
– количество слоев рекуррентной сети «number of RNN Layers»;
– количество эпох обучения «Number of epochs»;
– скорость обучения «Learning rate».
Параметрами первой модели были выбраны:
– количество нейронов в скрытом слое = 30;
– количество слоев рекуррентной сети = 1;
– количество эпох обучения = 50;
– скорость обучения = 0,05.
Результат представлен на рис. 2–4.
Параметрами второй модели были выбраны следующие:
– количество нейронов в скрытом слое = 15;
– количество слоев рекуррентной сети = 2;
– количество эпох обучения = 30;
– скорость обучения = 0,05.
Результат представлен на рис. 5–7.
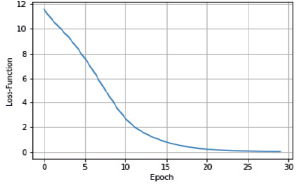
Рис. 5. Изменения функции ошибки обучения во второй модели

Рис. 6. Значения изменения ошибки обучения и точности предсказания во второй модели
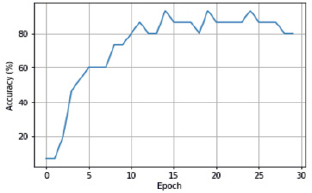
Рис. 7. Изменения точности предсказания во второй модели
Параметрами третьей модели были выбраны следующие:
– количество нейронов в скрытом слое = 15;
– количество слоев рекуррентной сети = 2;
– количество эпох обучения = 100;
– скорость обучения = 0,001.
Результат представлен на рис. 8–10.
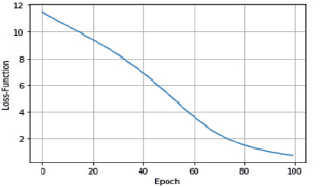
Рис. 8. Изменения ошибки обучения в третьей модели

Рис. 9. Значения изменения ошибки обучения и точности предсказания в третьей модели
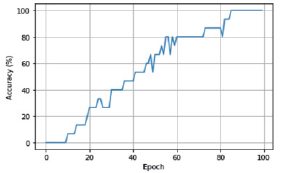
Рис. 10. Изменения точности предсказания в третьей модели
Согласно полученным результатам первая архитектура является оптимальной. Что и отражают полученные на основании первой модели предсказания для пользователя с visitorid = 56.
Заключение
По окончании обучения системы был произведен подбор параметров модели, для определения оптимальной архитектуры сети, основываясь на результатах, демонстрируемых полученными ошибками обучения и значениями точности предсказаний. Существует большое многообразие рекомендательных систем и алгоритмов их реализации. Но, несмотря на их пластичность, зачастую схожие системы дают значительно разнящиеся результаты, что отражается на работе системы в целом. В данном случае для разработанной системы была подобрана оптимальная архитектура для получения качественного предсказания.
Библиографическая ссылка
Крюкова Я.Э., Белов Ю.С. ПОДБОР ЗНАЧЕНИЙ ПАРАМЕТРОВ РАЗРАБОТАННОЙ РЕКОМЕНДАТЕЛЬНОЙ СИСТЕМЫ, ОСНОВАННОЙ НА АНАЛИЗЕ ПОВЕДЕНИЯ ПОЛЬЗОВАТЕЛЕЙ В СЕТИ // Научное обозрение. Технические науки. 2020. № 4. С. 46-51;URL: https://science-engineering.ru/en/article/view?id=1302 (дата обращения: 24.06.2026).