

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
METRICS REQUIRED TO COMPILE A RANKED LIST OF NEWS FOR A RECOMMENDATION SYSTEM

Благодаря технологии персонализированных рекомендаций, особенно популярных сегодня в области электронной коммерции, они также постепенно распространились на другие приложения, в том числе и персонализированные рекомендации новостей, которые обсуждаются в данной работе. Однако, поскольку новости имеют свои уникальные характеристики, ключевые технологии персонализированной рекомендации новостей немного отличаются от таковых в традиционной сфере электронной коммерции [1]. Ниже приведено сравнение и анализ ключевых технологий в персонализированной рекомендации новостей с разных точек зрения характеристик новостей.
Цель исследования: изучить факторы, влияющие на актуальность статьи, и привести структуру зависимости этих параметров друг от друга. На основе полученной модели описать исчерпывающую информацию об основных факторах, от которых зависит актуальность новостной статьи, и предложить способ балансировки точности рекомендации статьи с учетом параметра новизны.
Основные факторы, влияющие на актуальность статьи. Новости используются для быстрого и своевременного сообщения людям последних, своевременных и, главное, «ценных» фактов с помощью кратких текстов. «Недавний» фактор относится к контекстуальной информации новостей в смысле времени (т.е. когда новость произошла), а «ближайший» фактор относится к контекстуальной информации новостей в смысле местоположения (т.е. где новость произошла) [2]. Эти два фактора являются основной контекстуальной информацией, рассматриваемой в персонализированной новостной рекомендации. Кроме того, существует множество других контекстуальных факторов, таких как погода, сезон, будний день или выходные, плотность толпы и наличие сверстников среди окружения. В этой работе обсуждается только влияние контекстной информации о времени и местоположении на персонализированные рекомендации новостей. С популяризацией портативных мобильных устройств, таких как мобильный телефон, iPad и ноутбук, читатели новостей постепенно переходят с веб-приложений на мобильные. Благодаря портативности и гибкости мобильных устройств пользователи могут читать новости в любом месте и в любое время. Поэтому существует острая необходимость в изучении технологии персонализированных рекомендаций новостей, которая интегрирует контекстуальную информацию о времени и местоположении.
Учитывая все вышеописанное, на рисунке показана концептуальная модель факторов релевантности новостей. В этой модели на релевантность новостной статьи для отдельного пользователя может влиять ряд факторов, в том числе факторы, связанные со статьей, связанные с пользователем и так называемые глобальные факторы. Ниже подробно рассмотрены основные факторы.
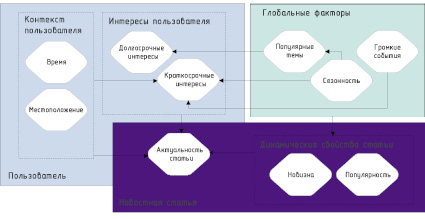
Концептуальная модель факторов релевантности новостной статьи
Цель персонализированной рекомендации новостей, зависящей от времени и местоположения, состоит в том, чтобы точно предсказать интересы пользователей к чтению в определенный момент времени (или период) и в определенном месте [3]. Если взять в качестве примера задачу рекомендации Top – N, то цель состоит в том, чтобы в итоге сформировать список новостей длиной N для пользователей, с учетом того, что список должен содержать только новости, интересные пользователю в определенный момент или в определенном месте. Детальный анализ технологии рекомендаций новостей с учетом фактора времени и фактора местоположения выглядит следующим образом.
Фактор времени. Влияние временной контекстуальной информации на персонализированную систему рекомендаций новостей и интересы пользователей является обширным и глубоким и в основном отражается в трех аспектах. Во-первых, интересы пользователей постоянно меняются. В зависимости от конкретного пользователя его интересы могут меняться постепенно или резко с течением времени. Для того чтобы точно извлечь текущие процентные предпочтения пользователей с постепенными изменениями интереса, их недавнее поведение должно быть также рассмотрено, поскольку недавнее поведение может наилучшим образом отражать текущие процентные предпочтения [4]. Во-вторых, новости имеют свой жизненный цикл. Жизненный цикл новостей короток. Сегодняшние «горячие» новости могут потерять свою актуальность завтра. Поэтому при рассмотрении вопроса о рекомендации новостей пользователям в данный момент необходимо различать, являются ли новости устаревшими или нет. В-третьих, новости имеют эффект сезонности. Например, различные громкие события, повторяющиеся с какой-то периодичностью, будут влиять на интересы пользователей, что является эффектом, вызванным изменением сезона. В общем случае при разработке алгоритмов рекомендаций необходимо учитывать данный фактор.
В связи с тем, что интересы пользователей меняются с течением времени, будет целесообразно делить интересы пользователей на два типа – долгосрочные предпочтения и краткосрочные предпочтения. Долгосрочные предпочтения пользователя относятся к общим предпочтениям, которые пользователь сформировал от начала использования системы до текущего времени. Краткосрочные предпочтения в основном основаны на недавнем поведении пользователя при чтении. Затем различные группы новостей, предпочитаемые разными пользователями, могут быть разделены, учитывая долгосрочные предпочтения пользователей, а затем с помощью краткосрочных предпочтений этот метод позволяет выбрать именно те новости, которые, скорее всего, будут актуальны для пользователя в данный момент времени. Этот метод полностью сочетает долгосрочные интересы пользователя с краткосрочными интересами, полностью учитывая характеристику интересов пользователей, изменяющихся постепенно с течением времени. Еще один важный фактор – продолжительность времени чтения. То есть это время, которое пользователи тратят на чтение новостей. Используя его, система может различать пользователей, которые внимательно читают новости, и пользователей, которые читают новости поверхностно. Корректировка традиционной формулы оценки пользователей с помощью данного фактора может в определенной степени повысить точность рекомендаций. Однако этот метод не учитывает внешние факторы, влияющие на чтение. Например, продолжительность чтения может увеличиться, если пользователь прервался и продолжил чтение через определенный промежуток времени.
В персонализированной рекомендации новостей временной контекст играет очень важную роль в методе рекомендации пользовательской коллаборативной фильтрации [5], особенно для измерения сходства. После нахождения похожей группы пользователей для пользователя u, краткосрочные предпочтения пользователей в этой группе, по-видимому, ближе к текущим новостным темам пользователя u, чем новостные темы, интересующие их некоторое время назад. Иными словами, на последние прочитанные новости пользователей, имеющих схожие интересы с целевым пользователем u, должно быть обращено больше внимания при рекомендации новостей целевому пользователю. Это особенно важно в области новостных рекомендаций с очень короткими жизненными циклами. Учитывая все вышеописанное, ниже приведена формула расчета сходства пользователей (модернизированная формула в алгоритме user-based коллаборативной фильтрации) (1).
В уравнении (1) к числителю формулы добавляется коэффициент затухания времени λ для новостей, которыми поделились пользователь u и пользователь v. N(u) и N(v) означает коллекцию новостей, которую читают пользователь u или v соответственно. tui представляет собой временную точку отсчета i для пользователя u. Чем дальше временные точки i для u и v при чтении новостей, тем меньше их сходство. В результате найденные похожие друг на друга группы уникальных пользователей будут более точными.
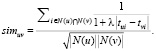 (1)
(1)
Фактор местоположения. Персонализированная новостная рекомендация, рассматривающая информацию о местоположении, в основном рассматривает траекторию движения пользователя, а также построение и распознавание сети часто посещаемых мест. В частности, точки местоположения пользователя, изменяющиеся с течением времени, соединяются последовательно для формирования траектории движения. Это повторяется для каждого пользователя, зарегистрированного в системе. После этого анализируются различные маршруты относительно позиции всех пользователей на основе сети траекторий, чтобы сформулировать новый метод расчета ближайшего пользователя [6]. Даже при рассмотрении информации о перемещении только одного пользователя, будущие предпочтения в тематике новостей можно предсказать в соответствии с собственными траекториями перемещения конкретного пользователя. Затем пользователю будут предложены новости, которые, скорее всего, будут ему интересны в диапазоне прогнозируемой позиции, чтобы реализовать основанную на местоположении персонализированную рекомендацию новостей.
Фактор оценки новизны новостной статьи. Новизна рекомендуемого элемента может быть определена по-разному, например как неочевидность предложений элемента, или с точки зрения того, насколько отличается элемент по отношению к тому, что уже было предложено и оценено пользователем или группой пользователей. Однако рекомендация исключительно новых или непопулярных товаров может иметь ограниченную ценность, если они не соответствуют интересам пользователей [7]. Поэтому цель рекомендательной системы часто состоит в том, чтобы сбалансировать эти конкурирующие факторы, то есть сделать несколько более новые и, следовательно, рискованные рекомендации, в то же время обеспечивая высокую точность.
В литературе был предложен ряд способов количественной оценки степени новизны, в том числе альтернативные способы учета информации о популярности или расстояния элемента-кандидата до профиля пользователя. Например, можно измерять новизну как противоположность популярности статьи, исходя из предположения, что менее популярные статьи с большей вероятностью будут неизвестны пользователям и их рекомендации приведут к более высоким уровням новизны.
Что касается рассмотрения компромиссных ситуаций, то возможны различные технические подходы. Можно, например, попытаться повторно ранжировать оптимизированный по точности список рекомендаций либо для достижения глобально определенных уровней качества, либо для получения списков рекомендаций, соответствующих предпочтениям отдельных пользователей. Другой подход заключается в варьировании весов различных факторов, чтобы найти конфигурацию, которая приводит как к высокой точности, так и к хорошей новизне.
Наконец, можно попытаться включить рассмотрение компромиссов в фазу обучения, например, используя соответствующий термин регуляризации. Существует метод под названием Novelty-aware Matrix Factorization (NMF), который пытается одновременно рекомендовать точные и новые элементы. Предлагаемый ими подход к регуляризации носит точечный характер, что означает, что новизна каждого элемента-кандидата рассматривается индивидуально.
Балансировка точности рекомендации с учетом новизны. Конечной задачей системы рекомендации новостей является составление ранжированного списка элементов (Top-N рекомендация), которые, по предсказанию системы, пользователь будет читать следующими [8]. В связи с этим определим функцию потерь на основе ранжирования для поставленной задачи.
Введем термин регуляризации новизны в функцию потерь с целью включения аспекта новизны статьи непосредственно в процесс обучения модели. Этот параметр регуляризации может быть настроен для достижения баланса между точностью рекомендации и новизной предлагаемой статьи в соответствии с желаемым эффектом для конкретного приложения.
В данной статье предлагаемый подход определения новизны основан на методе непопулярности элемента. То есть, как писалось выше, можно измерять новизну как противоположность популярности статьи, исходя из предположения, что менее популярные статьи с большей вероятностью будут неизвестны пользователям и их рекомендации приведут к более высоким уровням новизны [9].
Таким образом, предлагаемый фактор новизны направлен на смещение рекомендации нейронной сети в сторону новых элементов в системе. В таком случае это не повлияет негативным образом на элементы из положительной выборки (те, на которые пользователи кликнули), а только на элементы из отрицательной (которые еще не были просмотрены). Новизна отрицательных элементов оценивается по их вероятности быть следующей предложенной статьей в последовательности (апостериорная вероятность того, что статья будет прочитана следующей во время текущего пользовательского сеанса), чтобы выдвинуть эти элементы на первое место в списке рекомендованных статей, которые будут одновременно новыми и релевантными для конкретного пользователя.
Функция потерь для фактора новизны определяется в уравнении
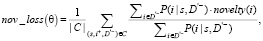 (2)
(2)
где C – множество кликов пользователя, доступных для обучения, D'– – случайные элементы из отрицательной выборки, за исключением положительной выборки, i – идентификатор статьи, s – текущий пользовательский сеанс. Значение новизны элементов оценивается по их прогнозируемой релевантности P(i|s, D'–, чтобы поднять к вершине списка как новые, так и релевантные элементы.
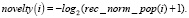 (3)
(3)
Метрика новизны в уравнении (3) определяется на основе нормализованной популярности статьи за последнее время. Отрицательный логарифм в уравнении увеличивает значение метрики новизны для long-tail элементов (элементы, которые мало кто видел).
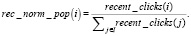 (4)
(4)
Вычисление нормализованной популярности статьи суммируется до максимального значения 1.0 для всех рекомендуемых элементов (набор I), как показано в уравнении (4). Поскольку балансировка актуальна только для тех статей, которые стали популярны недавно, в расчетах рассматриваются только клики, полученные статьей в течение определенного периода времени (например, за последний час). Данная информация возвращается функцией recent_clicks(?).
Результаты исследования и их обсуждение
В процессе написания данной статьи были изучены факторы, влияющие на актуальность статьи, и приведена структура зависимости этих параметров друг от друга. На основе полученной модели описана исчерпывающая информация об основных факторах (таких как время и связанные с этим профили предпочтений (долгосрочный и краткосрочный), местоположение и новизна новостной статьи), от которых зависит актуальность новостной статьи, и предложен способ балансировки точности рекомендации статьи с учетом параметра новизны с последующим выводом функции потерь для учета этого фактора.
Заключение
Роль персонифицированных рекомендаций в процессе цифровизации всех областей интернета также становится все более важной, особенно в области новостей. Одной из важнейших задач сегодня является интеграции существующих персонализированных рекомендательных технологий в интернет-новости; другая не менее важная задача – построить оптимальную модель предпочтений пользователей, всесторонне учитывающую множество факторов. Решая эту важную задачу, появляется возможность создания новостной рекомендательной системы с исчерпывающей контекстуальной информацией. Изучение масштабируемых контекстно-зависимых методик рекомендаций имеет большое значение для продвижения в практических приложениях. До сих пор существуют две проблемы в исследовании контекстно-зависимых рекомендательных систем. Одна из проблем заключается в том, что каждая система рекомендаций в основном предназначена для конкретного сценария применения, что ограничивает масштабируемость данной системы. Другая проблема заключается в том, что все контекстно-зависимые рекомендательные системы содержат одинаковую контекстуальную информацию, но, несмотря на это, одна и та же контекстуальная информация может обладать различной структурой хранения и обработки, что ограничивает обмен данными между различными контекстно-зависимыми рекомендательными службами.
Библиографическая ссылка
Колебцев В.И., Белов Ю.С. МЕТРИКИ, НЕОБХОДИМЫЕ ДЛЯ СОСТАВЛЕНИЯ РАНЖИРОВАННОГО СПИСКА НОВОСТЕЙ ДЛЯ РЕКОМЕНДАТЕЛЬНОЙ СИСТЕМЫ // Научное обозрение. Технические науки. 2021. № 5. С. 10-14;URL: https://science-engineering.ru/en/article/view?id=1369 (дата обращения: 21.07.2026).