

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
DESIGN OF A ROAD SIGN DETECTION AND RECOGNITION SYSTEM

Интеллектуальные транспортные системы (ИТС) обладают огромным потенциалом для экономии времени, денег, спасения жизней и улучшения окружающей среды. Распознавание дорожных знаков – одна из важных областей в ИТС. Это связано с важностью дорожных знаков и светофоров в повседневной жизни. Они определяют визуальный язык, который могут интерпретировать водители. Они отображают текущую дорожную ситуацию, показывают опасности и трудности вокруг водителей, предупреждают их и помогают им в навигации, предоставляя полезную информацию, которая делает вождение безопасным и удобным. Идентификация дорожных знаков осуществляется в два основных этапа: обнаружение и распознавание. На этапе обнаружения изображение предварительно обрабатывается, улучшается и сегментируется в соответствии со свойствами знака, такими как цвет или форма. Результатом является сегментированное изображение, содержащее потенциальные области, которые могут быть распознаны как возможные дорожные знаки. Эффективность и скорость обнаружения являются важными факторами, которые играют важную роль во всем процессе, поскольку они сокращают пространство поиска и указывают только на потенциальные области. На этапе распознавания каждый из кандидатов проверяется на соответствие определенному набору признаков (шаблону), чтобы решить, входит ли он в группу дорожных знаков или нет, а затем в соответствии с этими характеристиками они классифицируются в разные группы [1].
Цель исследования: разработать систему обнаружения и распознавания дорожных знаков с надежными функциями извлечения и представления и обеспечивающую неизменность освещения, масштаба и положения.
Описание модели. Для решения задачи распознавания становится целесообразным комбинировать несколько алгоритмов. Работа системы обнаружения и распознавания дорожных знаков происходит в два этапа: обнаружение дорожных знаков; распознавание дорожных знаков. Общая модель системы распознавания дорожных знаков состоит из ряда взаимосвязанных модулей.
Цветовая кодировка. Цвет предупреждающих дорожных знаков является ценным ключом к распознаванию знаков. Однако, поскольку дорожные знаки размещены в различных условиях освещения, трудно добиться обнаружения инварианта освещенности, используя непосредственно абсолютные значения цвета. Поэтому мы хотели бы кодировать информацию о цвете косвенно и использовать относительный вид вместо абсолютных значений на разных цветовых слоях [2].
Возьмем, к примеру, знак остановки. На слое R в пространстве RGB, поскольку и белый, и красный цвет пикселей имеют высокие значения интенсивности, величина градиента на этом слое мала. Однако на слоях G и B красные пиксели имеют низкое значение, в то время как значение интенсивности белых пикселей все еще высокое; таким образом, величина градиента на этих краях между белыми и красными пикселями высока. В результате градиент одного и того же пикселя на разных слоях может иметь очень разные значения, и эти значения коррелированы. Поэтому мы объединяем значения градиента на трех слоях в вектор и нормализуем его, используя сумму значений градиента по трем слоям.
Функция на основе HOG. Как и SIFT, мы адаптировали HOG для извлечения функций. Есть два преимущества использования методов на основе HOG. Во-первых, дорожные знаки имеют отличительную форму, а узоры на разных слоях могут иметь четкие края. Следовательно, градиент может эффективно улавливать эти особенности. Во-вторых, использование HOG может помочь добиться масштабной инвариантности.
Во-первых, изображение разделяется на квадратные области 3 на 3 и определяются 14 подблоков, показанных как заштрихованные области на рис. 1. Во-вторых, проектируем 15 шаблонов и делим диапазон ориентации [0 2π] на 8 ячеек, как показано на рис. 2. Каждый шаблон представляет собой квадратный блок с заштрихованной ячейкой [3].
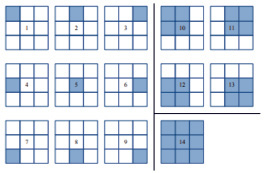
Рис. 1. Подблоки изображения
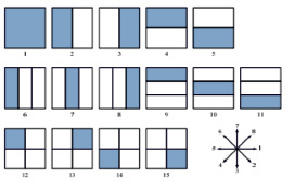
Рис. 2. Шаблоны и подборки ориентации
Учитывая цветное изображение, функция оценивается на разных слоях в i-м подблоке с использованием j-го шаблона и k-й ориентации. Каждая функция обозначается 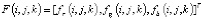 , где три компоненты соответствуют трем слоям RGB. Обозначим i-й подблок Bi и заштрихованную область ячейки в j-м шаблоне Cj. Затем для fr (i, j, k) мы сначала вычисляем градиент в каждом пикселе (x, y) на слое R как
, где три компоненты соответствуют трем слоям RGB. Обозначим i-й подблок Bi и заштрихованную область ячейки в j-м шаблоне Cj. Затем для fr (i, j, k) мы сначала вычисляем градиент в каждом пикселе (x, y) на слое R как
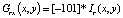 ,
,
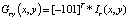 ;
;
сила градиента в точке (x, y) равна
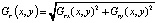 ,
,
и ориентация:
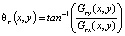 .
.
Помните, что мы разделили диапазон ориентации [0 2π] на 8 интервалов и обозначили значение k-го интервала как
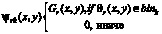 .
.
Значение признака для fr (i, j, k) определяется как
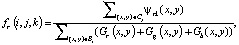
где Gg(x, y) и Gb(x, y) – величины градиента на слоях G и B соответственно.
Аналогично имеем
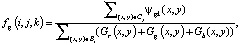
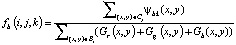 .
.
Наконец, у нас есть
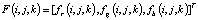 .
.
Поскольку существует 14 подблоков, 15 шаблонов и 8 ориентаций, у нас всего 14×15×8 = 1680 функций.
Интегральные изображения широко используются в наших алгоритмах и, таким образом, сокращают повторные вычисления. Предварительное вычисление обеспечивает быстрое вычисление при предварительной обработке, а также включает этапы извлечения. Следующая формула показывает вычисление целостного изображения. Любое показание в интегральном изображении представляет собой сумму от (1,1) до этой точки.
Таким образом, суммирование области C может быть выполнено с использованием только четырех арифметических вычислений показаний в четырех углах этой области.
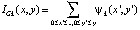
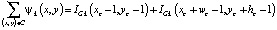
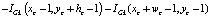 .
.
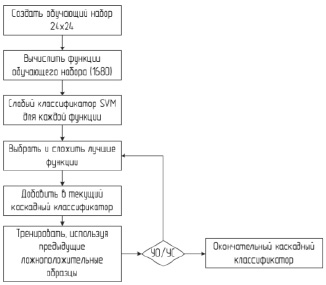
Рис. 3. Блок-схема фазы обучения
Методы обучения. Набор из 1680 функций является избыточным. Следовательно, нам необходимо выбрать признаки для каждого из признаков, которые могут лучше всего описать и различить их. Более того, процесс выбора признаков переплетается с процессом построения классификатора. Обзор этапа обучения показан на рис. 3. Наша цель – построить каскадный классификатор для каждого из признаков [4].

Рис. 4. Пример изображений в наборе данных
Во-первых, для каждого знака мы создали обучающий набор, в котором изображения текущего обучающего знака являются положительными образцами, а все другие знаки и случайно выбранные изображения являются отрицательными образцами. После этого вычисляются 1680 характеристик для каждого из образцов.
Во-вторых, для каждой функции мы используем машину опорных векторов с ядром RPF, чтобы классифицировать все образцы. Поскольку количество отрицательных образцов примерно в четыре раза больше, чем количество положительных образцов, мы скорректировали параметры штрафа члена ошибки для двух классов, чтобы справиться с этой несбалансированной ситуацией. Кроме того, мы использовали разные наборы параметров штрафа с разным акцентом на положительные и отрицательные образцы, чтобы найти компромисс между частотой обнаружения и частотой ложных срабатываний.
В-третьих, после получения результатов классификации с использованием каждой функции мы выбрали несколько основных функций с наивысшим уровнем обнаружения и относительно меньшим количеством ложных срабатываний. Мы перечислили различные варианты выбора и комбинации этих функций, и для каждой комбинации мы сложили выбранные функции как функцию более высокого измерения, а затем использовали новую отдельную функцию для классификации обучающего набора. Новая функция с наивысшим уровнем обнаружения и относительно меньшей частотой ложных срабатываний выбрана в качестве единственного классификатора первого уровня [5].
В-четвертых, получив единый классификатор первого этапа, мы использовали другой набор для проверки, чтобы проверить текущий классификатор, чтобы убедиться, что он имеет очень высокий уровень обнаружения (>98,5 %), и записали ложноположительные образцы. Затем мы объединили ложноположительные образцы как из обучающего набора, так и из набора проверки, как новый набор отрицательных образцов. Этот новый набор отрицательных выборок и положительные образцы из обучающего набора объединяются в новый обучающий набор.
Наконец, используя новый обучающий набор, мы повторили шаги со второго по четвертый, чтобы сформировать еще один новый одноэтапный классификатор, который каскадируется после текущего классификатора. Эта процедура повторяется до тех пор, пока каскадный классификатор не достигнет предопределенной частоты ложных срабатываний, имея при этом степень обнаружения выше, чем предопределенная наименьшая частота обнаружения [6].
Каскадные детекторы знаков. Каскадные классификаторы для разных знаков последовательно комбинируются для формирования окончательного классификатора предупреждающих дорожных знаков. Как показано на рис. 5, входное изображение сначала проверяется классификатором знака остановки. Если изображение проходит все этапы каскадного классификатора знаков остановки, мы помечаем его как возможную область знака остановки. В противном случае мы передаем его в классификатор знака «Въезд запрещен», и та же процедура выполняется для классификаторов без поворота налево и выхода. Если мы обнаруживаем, что текущее изображение не принадлежит ни к одному из этих знаков, мы объявляем его областью, которая не является знаком [7].
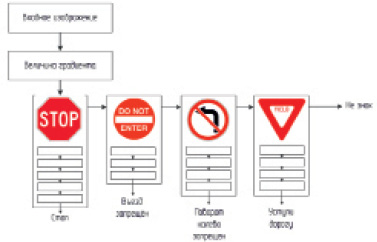
Рис. 5. Каскадные детекторы знаков
Заключение
В последнее десятилетие большой объем работы был проделан в области обнаружения и распознавания дорожных знаков. В этом исследовании принимали участие многие компании и исследовательские группы, и были достигнуты очень хорошие результаты. Распознавание дорожных знаков – это метод, который использует компьютерное зрение и искусственный интеллект для извлечения дорожных знаков из изображений на открытом воздухе в условиях неконтролируемого освещения, когда эти знаки могут быть закрыты другими объектами и могут иметь различные проблемы, такие как выцветание цветов, дезориентация и вариации по форме и размеру.
В данной статье продемонстрирована система обнаружения и распознавания дорожных знаков с надежными функциями извлечения и представления. Система также может обеспечить неизменность освещения, масштаба и положения. Обладая чрезмерно полным набором функций, система способна полностью выделять отличительные черты для различных дорожных знаков и, следовательно, может быть легко расширена для размещения новых знаков [8].
Библиографическая ссылка
Чулин К.В., Белов Ю.С. ПРОЕКТИРОВАНИЕ СИСТЕМЫ ОБНАРУЖЕНИЯ И РАСПОЗНАВАНИЯ ДОРОЖНЫХ ЗНАКОВ // Научное обозрение. Технические науки. 2021. № 6. С. 22-27;URL: https://science-engineering.ru/en/article/view?id=1376 (дата обращения: 02.08.2026).