

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Technical science
ISSN 2500-0799
ПИ №ФС77-57440
APPLICATION OF MACHINE LEARNING FOR PREDICTING PACKET LOSS IN WI-FI NETWORKS

Введение
В условиях постоянного роста объемов беспроводной передачи данных вопросы обеспечения качества обслуживания (QoS) становятся всё более актуальными. Потери пакетов в Wi-Fi-сетях могут существенно снижать производительность приложений, особенно тех, которые чувствительны к задержкам и потерям, таких как видеоконференции, VoIP и онлайн-игры [1]. Прогнозирование потерь пакетов позволяет принимать превентивные меры для оптимизации сетевых параметров и улучшения условий эксплуатации [2]. Одним из перспективных подходов к решению рассматриваемой задачи является применение методов машинного обучения (ML) [3].
В отличие от предыдущих исследований, сосредоточенных на применении отдельных алгоритмов (например, Random Forest [2]), работа представляет комплексное сравнение пяти различных моделей машинного обучения, включая ансамблевые и нейросетевые подходы, что позволяет объективно оценить их пригодность к задачам прогнозирования потерь пакетов и определить ключевые параметры среды, влияющие на качество соединения.
Цель исследования – анализ возможности применения различных алгоритмов машинного обучения для прогнозирования потерь пакетов в Wi-Fi-сетях на основе параметров сетевого трафика и характеристик окружающей среды.
Материалы и методы исследования
Для проведения исследования собрана выборка сетевых данных с использованием программного обеспечения Wireshark и специализированных скриптов на Python. Один из таких скриптов выполнял захват сетевых пакетов с помощью библиотеки Pyshark – обёртки над Wireshark. Скрипт запускался на ноутбуке, подключённом к Wi-Fi-сети, и сохранял данные о каждом пакете (время, источник, уровень сигнала, протокол, длина и наличие ошибок) в формате CSV. Помимо этого, второй скрипт с помощью iwconfig и iwlist на Linux-платформе снимал информацию о параметрах сигнала и окружения, таких как уровень шума, используемый канал и количество подключённых устройств. Собранные данные затем объединялись в единый датасет с меткой о наличии или отсутствии потерь пакетов. Сбор данных проводился в различных условиях (плотность трафика, количество клиентов, расстояние до точки доступа). В качестве признаков (features) рассматривались следующие параметры: уровень сигнала (RSSI – Received Signal Strength Indicator), длина пакета (байт), отношение сигнал/шум (SNR – Signal-to-Noise Ratio), количество подключенных клиентов и загруженность канала [4].
Предварительная обработка данных включала очистку от пропущенных значений, нормализацию и кодирование категориальных признаков. Для построения моделей прогнозирования использовались логистическая регрессия, метод опорных векторов (SVM), случайный лес (Random Forest), градиентный бустинг (XGBoost) и многослойный перцептрон (MLP). У каждой модели есть свои особенности:
логистическая регрессия – базовая модель классификации, используемая для предсказания вероятности наступления бинарного события;
метод опорных векторов (SVM) – алгоритм строит оптимальную гиперплоскость для разделения классов в пространстве признаков;
случайный лес (Random Forest) – ансамблевый метод, основанный на построении множества деревьев решений и агрегировании их результатов;
градиентный бустинг (XGBoost) – улучшенный ансамблевый алгоритм, обучает модели последовательно, минимизируя ошибку предыдущих;
многослойный перцептрон (MLP) – тип искусственной нейронной сети, состоящий из входного, одного или нескольких скрытых и выходного слоя, способный моделировать сложные нелинейные зависимости [5-7].
Для оценки качества моделей использовались метрики: точность (accuracy), полнота (recall), F1-мера и площадь под кривой ROC (AUC-ROC) [8].
Точность (Accuracy) – доля правильно классифицированных примеров из общего числа наблюдений:
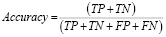 , (1)
, (1)
где TP – истинно положительные,
TN – истинно отрицательные,
FP – ложно положительные,
FN – ложно отрицательные.
Полнота (Recall) – способность модели обнаруживать все положительные случаи:
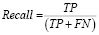 , (2)
, (2)
F1-мера – гармоническое среднее между точностью (precision) и полнотой:
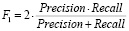 , (3)
, (3)
где
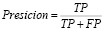 (4)
(4)
AUC-ROC – интегральная метрика, отображающая способность модели различать положительные и отрицательные классы на разных порогах вероятности. Она определяется как площадь под ROC-кривой, которая строится на основе значений True Positive Rate (TPR) и False Positive Rate (FPR) [9]:
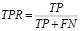 (5)
(5)
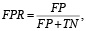 (6)
(6)
Значение AUC колеблется от 0 до 1, где 1 соответствует идеальной классификации, а 0.5 – случайному угадыванию (худший результат).
Разделение данных на обучающую и тестовую выборки производилось в пропорции 80:20 с использованием стратифицированной выборки [10].
Результаты исследования и их обсуждение
Каждая модель была протестирована на валидационном наборе данных (20% от всей выборки). Основываясь на результатах тестирования моделей, проведенных нами, была составлена таблица 1 и построены графики AUC-ROC (рисунки 1–5). Значения TPR и FPR для построения AUC-ROC кривых вычислялись программно, а после вычисления были экспортированы в Exсel-таблицу с помощью скрипта на языке Python для дальнейшего использования. Наивысшую точность и полноту продемонстрировали ансамблевые модели случайного леса и градиентного бустинга, с небольшим преимуществом XGBoost, точность которого достигла 92%, F1-мера – 0.85, полнота – 0.85 и AUC-ROC – 0.94. У модели на втором месте – случайного леса – точность 91%, F1-мера – 0.82, преимущество перед MLP в показателе полноты (0.81 у Random Forest против 0.77 у MLP). Модели логистической регрессии и SVM продемонстрировали удовлетворительную точность (89% и 91% соответственно), однако их показатели по полноте оказались ниже, чем у других моделей (0.62 и 0.69 соответственно), что делает их менее предпочтительными в условиях, когда важно минимизировать пропущенные случаи потерь.
Таблица 1
Сравнение эффективности моделей машинного обучения
|
Модель |
Точность |
Полнота |
F1-мера |
AUC-ROC |
|
Логистическая регрессия |
0,89 |
0,62 |
0,74 |
0,95 |
|
SVM |
0,91 |
0,69 |
0,80 |
0,96 |
|
Случайный лес |
0,91 |
0,81 |
0,82 |
0,95 |
|
XGBoost |
0,92 |
0,85 |
0,85 |
0,95 |
|
MLP |
0,91 |
0,77 |
0,82 |
0,95 |
Источник: составлено авторами.
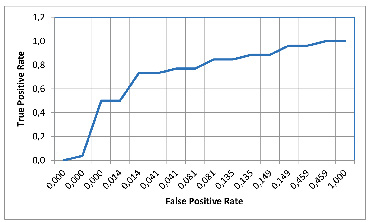
Рис. 1. ROC-кривая для модели логистической регрессии Источник: составлено авторами
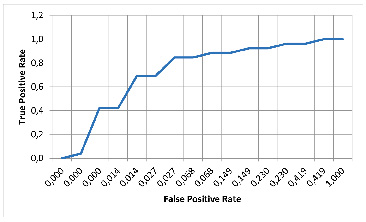
Рис. 2. ROC-кривая для модели SVM Источник: составлено авторами
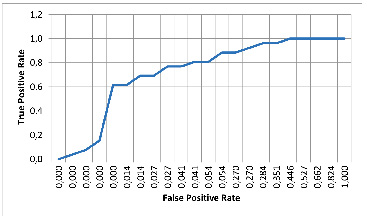
Рис. 3. ROC-кривая для модели случайного леса Источник: составлено авторами
Результаты показывают, что алгоритмы ансамблевого обучения (Random Forest и XGBoost) лучше справляются с задачей прогнозирования потерь пакетов, скорее всего благодаря тому, что они способны выявлять сложные нелинейные зависимости между признаками [11]. Помимо этого, важность признаков, определённая скриптом на языке Python с помощью XGBoost, показала, что количество подключённых клиентов, загруженность канала и отношение сигнал/шум (SNR) являются наиболее влиятельными параметрами в случае прогнозирования потери пакетов [12]. Важность признаков (веса признаков), определенная с помощью модели XGBoost, объединена в таблице 2.
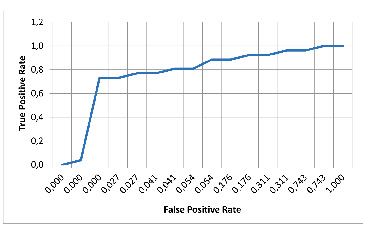
Рис. 4. ROC-кривая для модели XGBoost Источник: составлено авторами
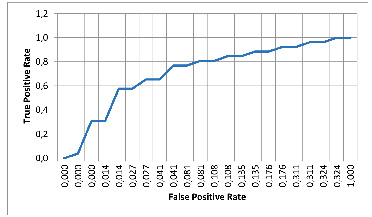
Рис. 5. ROC-кривая для модели MLP Источник: составлено авторами
Таблица 2
Важность признаков для XGBoost
|
Признак |
Вес признака |
|
Количество подключенных клиентов |
0,635 |
|
Загруженность канала |
0,144 |
|
SNR |
0,107 |
|
Сила сигнала |
0,068 |
|
Длина пакета |
0,045 |
Источник: составлено авторами.
В отличие от работы Giannakou и др. [2], где рассматривалась лишь одна модель и ограниченный набор признаков, выполненное авторами исследование демонстрирует преимущество ансамблевых и нейросетевых методов при наличии полевых данных различной природы, что способствует расширению понимания применения методов ML к задачам QoS в беспроводных сетях.
Выводы
Проведённое исследование показало, что применение алгоритмов машинного обучения, в частности алгоритмов ансамблевого типа – XGBoost и случайного леса, позволяет с высокой точностью прогнозировать потери пакетов в Wi-Fi-сетях. Эти модели могут быть эффективно интегрированы в системы мониторинга и управления беспроводной инфраструктурой для принятия своевременных корректирующих мер. Выявленные ключевые признаки позволяют сфокусировать внимание на наиболее критичных аспектах при оптимизации параметров сети. В будущем возможно расширение исследования с использованием более обширных и разнообразных исходных данных, а также внедрение моделей в реальное оборудование точек доступа.
Библиографическая ссылка
Ананченко И.В., Добровольский Д.К. ПРИМЕНЕНИЕ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПРОГНОЗИРОВАНИЯ ПОТЕРЬ ПАКЕТОВ В WI-FI-СЕТЯХ // Научное обозрение. Технические науки. 2025. № 3. С. 16-21;URL: https://science-engineering.ru/en/article/view?id=1509 (дата обращения: 01.07.2026).
DOI: https://doi.org/10.17513/srts.1509