

 science-review.ru
science-review.ru
Распознавание речи – это возможность машины или программы идентифицировать слова и фразы на устном языке и преобразовать их в машиночитаемый формат [1]. Речь представляет собой последовательность звуков. Звук, в свою очередь, представляет собой суперпозицию звуковых волн разных частот. Волна, как известно из физики, характеризуется двумя атрибутами – амплитудой и скоростью. Чтобы сохранить аудиосигнал на цифровом носителе, его необходимо разделить на несколько промежутков и принять определенное «усредненное» значение для каждого из них. Таким образом, механические колебания преобразуются в набор чисел, подходящих для обработки на современных компьютерах. Рудиментарное программное обеспечение для распознавания речи имеет ограниченный словарный запас слов и фраз, и поэтому оно может идентифицировать слова, только если произношение очень четкое. Более сложное программное обеспечение имеет возможность принимать естественную речь.
Распознавание речи работает на основе двух алгоритмов: акустического и языкового моделирования. Акустическое моделирование представляет собой взаимосвязь между лингвистическими единицами речи и аудиосигналов; языковое моделирование соответствует звукам с последовательностями слов, чтобы помочь различать слова, которые звучат одинаково. Процесс автоматического преобразования речи в текст может быть представлен в виде выражения
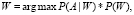
где argmax – значение аргумента, при котором выражение достигает максимума, P(A|W) – вероятность появления гипотезы по оценке акустической модели при условии появления гипотезы по оценке языковой модели, P(W) – вероятность появления гипотезы W по оценке языковой модели [1–2].
Речь захватывается чувствительным к звуку элементом в микрофоне, который преобразует переменное звуковое давление в эквивалентные изменения электрического сигнала, то есть тока или напряжения. Затем этот аналоговый сигнал отбирается и квантуется в цифровой бит-поток (формат). Далее происходит сэмплирование – процесс получения значений аналогового сигнала в отдельные моменты времени T, где квантование достигается путем преобразования амплитуды в каждый момент выборки в дискретное двоичное число с заданной длиной бит. Этот двухступенчатый процесс иногда называют модуляцией импульсного кода – PCM (Pulse Code Modulation). Количество выборок в секунду (частота) fs в Гц равно обратному периоду выборки, то есть fs = 1/T. Теорема выборки утверждает, что частота дискретизации должна быть как минимум в два раза выше самой высокой частотной составляющей, присутствующей в сигнале. Если используется меньшее количество образцов, возникает явление, известное как сглаживание, когда при повторной конструкции может появляться сигнал с более низкой частотой. Частота дискретизации для типичной речи приблизительно равна 3,3 кГц. Уже при 6–20 кГц требуется фильтр предварительной выборки или сглаживания, чтобы удалить частотные компоненты выше частоты Найквиста.
Производительность систем распознавания речи обычно оценивается с точки зрения точности и скорости. Точность оценивается как количество ошибок в слове, тогда как скорость измеряется с коэффициентом реального времени. Другие меры точности включают единичную ошибку и коэффициент успеха команды.
В процессе развития системы распознавания речи постепенно появлялись новые алгоритмы работы, такие как динамическое временное деформирование, скрытые марковские модели, нейронные сети и распознавание речи end-to-end [1, 3–4].
Dynamic Time Warping
Одним из самых ранних алгоритмов является алгоритм распознавания речи на основе динамического временного деформирования (DTW – Dynamic Time Warping). В анализе временных рядов динамическое временное деформирование является одним из алгоритмов для измерения сходства между двумя временными последовательностями. DTW применяется к временным последовательностям видео-, аудио- и графических данных. Действительно, любые данные, которые могут быть преобразованы в линейную последовательность, могут быть проанализированы с помощью DTW.
DTW заключается в измерении сходства между двумя последовательностями, которые могут меняться во времени или скорости. Для двух временных последовательностей Q = q1, q2, …, qn и C = c1, c2, …, cm это просто сумма квадратов расстояний от каждой k-ой точки одной последовательности до соответствующей точки другой. Расстояние DTW между двумя временными рядами рассчитывается на основе этого оптимального пути деформации, используя следующее уравнение:
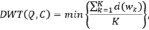 ,
,
где d(wk) = d(qi, cj) = (qi – cj)2 – матрица расстояний [5–6].
K в знаменателе используется для нормализации различных путей деформации с разной длиной. Поскольку DTW должен потенциально исследовать каждую ячейку в матрице деформирования, ее пространственная и временная сложность – O(nm)
Hidden Markov Model
На смену алгоритма DTW пришел более совершенный подход – скрытые Марковские модели (HMM – Hidden Markov Model). HMM являются статистическими моделями, которые выводят последовательность символов или величин и используются для распознавания речи, поскольку речевой сигнал можно рассматривать как кусочно-стационарный сигнал или кратковременный стационарный сигнал [6–7]. HMM определяется как совокупность λ = (A, B, π), где А – матрица вероятностей переходов, состоящая из элементов aij – вероятностей перехода из состояний i в j, В – матрица вероятностей наблюдения выходных значений, состоящая из элементов bi(ok) – вероятностей наблюдения в состоянии j вектора признаков ok, π – вектор вероятностей начальных состояний, состоящий из компонентов πi – вероятностей нахождения в i-ом состоянии в начальный момент времени. Находясь в состоянии j в момент времени t, функция прямого распространения вероятностей определяется как вероятность наблюдения последовательности O = (o1, o2, …, ot) [6]
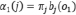 ,
,
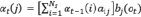 .
.
Вычисление αt(j) происходит рекурсивно. Дойдя до конца наблюдаемой последовательности, αT(j) складывается для всех состояний, получив вероятность наблюдения исходной последовательности O = (o1, o2, …, oT) [6],
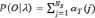 .
.
Данная вероятность используется при распознавании изолированных слов:
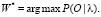
Каждое слово или фонема имеет различное распределение выходных данных. Фонемы моделируются с использованием трех различных состояний – начального, среднего и конечного. Существует два типа фонем: монофоны и трифоны. У монофонов наложение артикуляции игнорируется, собираются модели фонем, стоящих отдельно. У трифонов наложение артикуляции учитывается, при этом происходит построение отдельной модели для фонем, окруженных другими фонемами. Скрытая марковская модель для ряда слов или фонем создается путем объединения отдельных скрытых марковских моделей для каждого слова или фонемы [1, 7].
Artificial Neural Networks
Для оптимизации алгоритма HMM часто используют нейронные сети, которые предварительно обрабатывают речевой сигнала, например преобразование объектов или уменьшение размерности. Искусственные нейронные сети (ANN – Artificial Neural Networks) – это вычислительные системы, основанные на биологических нейронных сетях, которые составляют мозг животных. Такие системы изучают (постепенно улучшают производительность) задачи, рассматривая примеры, как правило, без специального программирования. Нейронные сети представляют собой устройства для сопоставления образцов с архитектурой обработки, основанной на нейронной структуре человеческого мозга [2, 7]. Они состоят из простых взаимосвязанных блоков обработки (нейронов). Каждое соединение (синапс) между нейронами может передавать сигнал от одного к другому. Приемный (постсинаптический) нейрон может обрабатывать сигнал, а затем подключать к нему нейроны. В обычных реализациях ANN синапсовый сигнал является реальным числом, а выход каждого нейрона вычисляется нелинейной функцией суммы его входов [8].
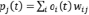 ,
,
где wij – вес соединений.
Нейроны и синапсы обычно имеют вес, который корректируется по мере продолжения обучения. Вес увеличивает или уменьшает силу сигнала, который он посылает через синапс. Нейроны могут иметь такой порог, что только в том случае, если совокупный сигнал пересекает это пороговое значение, посылаемый сигнал.
Как правило, нейроны организованы в слои. Различные слои могут выполнять различные виды преобразований на своих входах. Сигналы перемещаются от первого (входного) к последнему (выходному) слою. При оценке вероятности сегмента речи нейронные сети позволяют проводить тестирование естественным и эффективным образом. Недостатком нейронных сетей является неспособность моделировать временные зависимости [1–2].
Deep Neural Network
Разновидностью нейронных сетей являются глубокие нейронные сети (DNN – Deep Neural Network). Данный алгоритм представляет собой искусственную нейронную сеть с несколькими скрытыми слоями единиц между входным и выходным уровнями. Подобно мелким нейронным сетям, DNN могут моделировать сложные нелинейные отношения. Архитектуры DNN создают композиционные модели, в которых дополнительные слои позволяют составлять элементы из нижних слоев, обеспечивая огромную учебную способность и, следовательно, потенциал моделирования сложных моделей речевых данных. DNN сеть имеет входной слой x, скрытый слой s и выходной слой y. Входной слой состоит из вектора x(t), который является объединением вектора w(t), представляющим собой текущее слово, и вектора s(t – 1), который представляет собой выходные значения скрытого слоя, полученные на предыдущем шаге. Размер вектора w(t) равен размеру словаря. Выходной слой y(t) имеет тот же размер, что и w(t), и после изучения нейронной сети представляет собой вероятностное распределение следующего слова при данном предыдущем слове и состоянии скрытого слоя в предшествующий временной шаг [1–2]. Размер скрытого слоя обычно выбирается эмпирически. Все слои можно вычислить следующим образом:
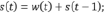 ,
,
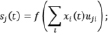 ,
,
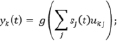 ,
,
где f(z) – сигмоидальная активационная функция:
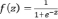 ,
,
g(z) – функция softmax:
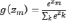 .
.
Алгоритм End-To-End
На сегодняшний день наиболее современным алгоритмом является алгоритм End-to-End поиска вероятности возрастания, называемый LAS (Likelihood Ascent Search). LAS – это модель распознавания речи от конца до конца. LAS учится транскрибировать аудиопоследовательность сигнала к последовательности слов, по одному символу за раз, без использования явных языковых моделей, таких как HMM. Он состоит из энкодера, который называется listener, и декодера, который назван speller. LAS моделирует каждый выход символа yi как условное распределение по сравнению с предыдущим символом [8–10]
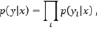 ,
,
где x = (x1,…, xT) – входная последовательность, y = (y1,…, ys) – выходная последовательность, причем элемент множества y может являться любым значением из букв, цифр или знаков. Данная модель является дискриминирующей и сквозной, поскольку она непосредственно предсказывает условную вероятность последовательности символов, учитывая акустический сигнал [10].
Главным преимуществом систем распознавания речи стала дружественность к пользователю. Они позволяют вводить данные или команды посредством речи без использования сенсорных или иных методов [3]. Недостаток же заключается в неспособности распознавать некоторые вариации произношения, а также отсутствие поддержки большинства языков за пределами английского языка и невозможности сортировать фоновый шум. Такие факторы могут привести к неточностям [7, 9].
Распознавание речи имеет широкий спектр применения. Простые голосовые команды могут использоваться для инициирования телефонных звонков, выбора радиостанций или воспроизведения музыки с совместимого смартфона или MP3-плеера. Так же распознавание речи позволяет общаться на разных языках.
Система распознавания речи также используется в военных нуждах. Распознаватели речи успешно работают на военных самолетах с приложениями, включающими: настройку радиочастот, управление системой автопилота, настройку координатных частот и параметров выпуска оружия и контроль полета. За последние десятилетия на вертолетах были проведены значительные программы испытаний систем распознавания речи, в частности в рамках исследований и разработок авионики США (AVRADA – Aviation Research And Development Activity) и Королевского аэрокосмического учреждения (RAS – Royal Aeronautical Societ) в Великобритании. В ходе исследований была выявлена основная проблема – достижения высокой точности распознавания при шуме. Эта проблема является неразрешенной и по сей день.
Подводя итоги, следует отметить, что, хотя система распознавания речи уже развивается давно, ее нельзя назвать совершенной, поскольку она имеет ограниченный потенциал из-за своей тривиальности. Хотя автоматические системы распознавания речи далеко не идеальны с точки зрения точности слова или задачи, надлежащим образом разработанные приложения все еще могут эффективно использовать существующую технологию для предоставления реальной ценности клиенту, о чем свидетельствует количество таких систем, которые ежедневно используются миллионами пользователей. Для оптимизации распознавания речи необходимо иметь большую базу данных слов, произносимых разными людьми в различном эмоциональном состоянии, используя разные записывающие устройства (телефон, микрофон, прослушивающее устройство). На сегодняшний день развитие алгоритмов распознавания речи не прекращается. В дальнейшем можно прогнозировать развитие систем распознавания речи в области усовершенствования нейронных сетей. Также обязательным требованием станет наличие обратных связей на различных уровнях и разработкой новых методов обучения таких нейронных сетей.
Библиографическая ссылка
Хлопенкова А.Ю., Белов Ю.С. ИССЛЕДОВАНИЕ АЛГОРИТМОВ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ АКУСТИЧЕСКОГО И ЯЗЫКОВОГО МОДЕЛИРОВАНИЯ // Научное обозрение. Технические науки. 2018. № 1. С. 32-36;URL: https://science-engineering.ru/ru/article/view?id=1177 (дата обращения: 16.07.2026).