

 science-review.ru
science-review.ru
FoundationDB – это распределенная база данных, предназначенная для обработки больших объемов структурированных данных в кластерах серверов. Она организует данные в качестве упорядоченных пар ключ-значение и использует транзакции ACID для всех операций. Эта база данных особенно хорошо подходит для нагрузок чтения/записи, но также имеет отличную производительность при интенсивных операциях записи [1].
Исходный драйвер от разработчиков FoundationDB предоставляет минимальный набор функций, основные из которых – сохранить ключ-значение, выбрать значение по ключу, выбрать значения по области ключей. Для реализации приложения данного функционала недостаточно, поэтому требуется разработать модель для хранения, индексирования, быстрых выборок и работы с очередями, которая будет хорошо работать по времени и оптимально использовать ресурсы диска.
Серверные курсоры. Чтобы преодолеть ограничение по величине и времени транзакции, выборка должна идти в индивидуальных микротранзакциях, сохраняя состояние в специальном объекте БД – курсоре. Перед началом выборки создается новый объект курсора со случайным идентификатором. Все курсоры должны считаться моделями и храниться в БД как отдельный тип данных [2].
Поля модели:
- идентификатор UUID;
- ID типа данных (2 байта);
- момент создания (для сборки мусора неуспешно закончившихся транзакций);
- срок жизни (в секундах);
- последний обработанный ключ (или значение 0х00, если выборка еще не началась).
Чтобы сделать структуру и поведение курсора универсальным между полным перебором и выборкой по индексу, предлагается использовать ID типа данных также и для индексов, нумеруя их как отдельный тип данных.
Предполагается, что создание курсора должно идти в отдельной независимой транзакции, предшествующей выборке, а идентификатор возвращается приложению. Он может использоваться как внутри приложения, так и снаружи. Например, возвращая ID курсора в фронтенд, клиент может использовать любой доступный сервер для продолжения выборки, что повышает отказоустойчивость [3].
Серверные курсоры также могут использоваться для организации постраничных выборок, но эта идея требует подробной проработки.
После использования курсор должен быть закрыт (а запись о нем в БД удалена). В случае ошибок обработки или некорректного использования, записи незакрытых курсоров могут быть проанализированы (для мониторинга системы – метрика корректности работы) и удалены сборщиком мусора.
Полный перебор с предикатом. Главное применение – выборки произвольного объема с любой сложностью условий, в том числе безусловные. Предикат – функция, принимающая на вход буфер объекта и возвращающая bool и error – решение, подходит элемент для выборки или нет. Для выборки только объектов определенного типа потребуется поле ключа «тип данных» (2 байта, описано выше).
type Predicat func(buf []byte) (bool, error)
Функция полного перебора должна принимать на вход контекст (для прерывания выборки), ID базы (2 байта), ID типа данных (2 байта), ID курсора (пустой, если новая выборка), функцию предиката для данного типа. Выходные параметры – канал буферов и ошибка. Канал нужен для того, чтобы а) сгладить разрывы между микротранзакциями запроса и б) корректно выйти в случае прерывания по контексту.
func SeqScan(ctx context.Context, db, objtype, cursor uint16, p Predicat) (<-chan []byte, error)
Композитные индексы. Главное применение – быстрые выборки по условиям равенства одного или нескольких полей [4]. Эти индексы выбираются в пользу набора простых индексов с реализацией join по следующим причинам:
- индексы по индивидуальным полям менее рационально используют место на диске;
- реализация функции Join для двух индексов будет иметь сложность не менее O(NlogN) в случае использования хеш-функции, а в худшем случае О(N^2). Для трех и более индексов – полиномиально, в то время как сложность выборки по композиту – О(N);
- композитные можно использовать повторно. Например, индекс по полям (А, B, C) можно также использовать для выборок по (А, В) и (А).
Как правило, при проектировании функционала в приложении заранее известна хотя бы часть выборок, которые будут необходимы. Это позволяет некоторые индексы создавать с самого начала. А поддержка драйвером полного перебора с предикатом позволяет создать инструменты миграции и актуализации индексов после запуска приложения в производственную эксплуатацию.
При создании индекса предлагается идентифицировать их записи кодом типа данных, как и структуры, а элементы индекса разделять между собой, чтобы избежать смешения данных. Если не разделять значения, то смешение приведет к ошибке выборки.
Например, пусть есть поля А = "ав" и B = "", а у другого объекта А = "а" и В = "в". Тогда в обоих случаях запись индекса без разделителей будет равна "ав". Для разделения значений предлагается использовать два вида разделителей: 0х00 и 0хFF. Использование 0х00 после пустого значения в сортированной коллекции будет аналогично правилу NULLS FIRST, а 0хFF соответственно NULLS LAST.
Итого, структура записи индекса по полям (А NULLS LAST, В NULLS FIRST, С NULLS LAST) будет выглядеть так:
<ID базы><ID типа индекса><значение А>0хFF<значение В>0x00 <значение С>0xFF<UUID объекта> = ""
Поскольку операции с полями FlatBuffer’а достаточно легковесные, для инвалидации индекса предлагается использовать функцию определения индекса и хранение исходного буфера в памяти [5]. Функция определения – подобна функции предиката, принимает на вход ID базы, буфер объекта, а на выходе дает массив байт ключа индекса (по схеме, как показано выше) и ошибку. Такая функция позволит определять полное значение индекса, в том числе его перенос в другую БД.
Драйвер должен использовать функцию определения индекса дважды – сначала передавая в него оригинальный (исходный) буфер объекта, а затем новый. Это позволит получить старое и новое значения ключа индекса без лишних выборок из БД. Затем драйвер должен удалить старое значение и записать новое. Важное ограничение – это должно быть сделано в той же транзакции, что и сохранение объекта, т.е. быть его неотъемлемой частью.
Модель очереди. Основная идея в том, что очередь – это специальный индекс, сортированный по дате, с отслеживанием изменения. Отслеживать легко с помощью инструмента watch клиента fdb.
Для удобства применения элемент очереди создается с моментом времени его предполагаемого выполнения. При этом механизм подписки должен возвращать только элементы с временем выполнения меньше текущего. Это позволит реализовать отложенные операции без лишних действий [6].
Для обеспечения гарантии обработки, при получении элемент очереди должен быть перемещен в особую коллекцию записей, которые еще не были подтверждены. Записи в этой коллекции не должны зависеть от времени, чтобы их можно было легко удалять без дополнительных данных.
Как и в случае типов данных и индексов, для идентификации очереди нужно использовать ID базы и ID типа данных. Для списка неподтвержденных элементов можно использовать тот же ID типа, но оградить его от основной очереди разделителем 0xFF.
Элемент очереди – это ID записи заранее известного приложению типа данных объектов, которые и являются реальными объектами задач.
Структуры элементов очереди:
? Обычный элемент. Выборка задач, готовых к выполнению: время задачи меньше или равно текущему времени
<ID базы><ID типа данных><Время выполнения задачи><ID объекта задачи> = ""
? Элемент списка неподтвержденных. Выборка неподтвержденных: 0xFF<задачи> меньше или равно 0xFF0xFF
<ID базы><ID типа данных>0xFF<ID объекта задачи> = ""
? // Элемент отслеживания изменений (для watch)
<ID базы><ID типа данных>0xFF0xFF = "<момент последнего обновления>"
Алгоритм получения данных из очереди:
1. Выбрать ID готовых задач (задачи меньше или равно текущее время). Либо согласно установленному лимиту, либо все готовые.
2. По списку ID выбрать сами задачи и вернуть их.
3. Переместить записи в список неподтвержденных.
4. Если требуется продолжать выборку, устанавливается watch.
5. Как только watch срабатывает, переход к п. 1.
Блок-схема алгоритма получения данных из очереди представлена на рисунке.
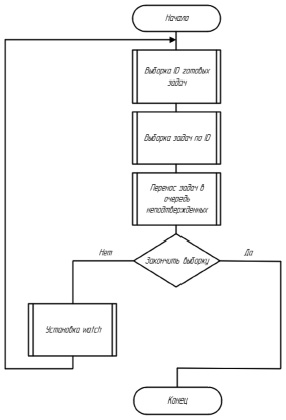
Блок-схема алгоритма получения данных из очереди
Исходя из алгоритма, функция получения элементов очереди должна принимать на вход ID базы, ID типа данных очереди, ID типа данных задач, а возвращать канал буферов объектов и ошибку. Объект очереди должен иметь возможность выдать все неподтвержденные задачи. Также объект очереди должен иметь функцию подтверждения получения задачи.
Возникает вопрос, абстрагировать ли работу с очередями от коллекций объектов? Если да, то работа везде идет только с обезличенными идентификаторами. Это упрощает код и вид реализации, но забота о загрузке и сохранении объектов ложится на вызывающую сторону. Отрицательный момент: поскольку метод возвращает канал, это будет стимулировать разработчиков организовывать загрузку объектов из БД по одному, что пагубно скажется на производительности [7].
Пример интерфейса:
// Конструктор конкретной очереди в конкретной базе
func NewQueue(db, qtype uint16) Queue {}
type Queue interface {
Ack(uuid.UUID) error
Pub(time.Time, uuid.UUID) error
Sub() (<-chan uuid.UUID, error)
Lost() ([]uuid.UUID, error)
}
С другой стороны, на стороне обработчика очереди Sub реально загрузка из БД идет порциями. Оптимистично можно предполагать, что размер порции больше одного объекта, что делает возможной пакетную загрузку объектов из БД на стороне очереди, но усложняет код и интерфейс взаимодействия, а также может оказаться потенциально лишней операцией, к примеру, если нужно получить только изменения в идентификаторах, без подгрузки объекта.
Пример интерфейса:
// Конструктор конкретной очереди в конкретной базе
func NewQueue(db, qtype, otype uint16) Queue {}
type Queue interface {
Ack(uuid.UUID) error
Pub(time.Time, uuid.UUID, []byte) error
Sub() (<-chan []byte, error)
Lost() ([][]byte, error)
}
Компромиссный интерфейс, объединяющий оба подхода, но из-за этого менее понятный и избыточный:
// Конструктор конкретной очереди в конкретной базе
func NewQueue(db, qtype, otype uint16) Queue {}
type Queue interface {
Ack(uuid.UUID) error
Pub(time.Time, uuid.UUID, []byte) error
PubID(time.Time, uuid.UUID) error
Sub() (<-chan []byte, error)
SubIDs() (<-chan uuid.UUID, error)
Lost() ([][]byte, error)
LostIDs() ([]uuid.UUID, error)
}
Заключение
В результате исследования была реализована модель для выборок, индексирования объектов и работы с очередями, которая максимизирует скорости работы с неопределенно большими объемами объектов, минимизирует занимаемое место в БД, преодолевает лимиты FoundationDB на длительность и размер транзакций, минимизирует выделение памяти на индексы.
Библиографическая ссылка
Селиванов П.А., Гришунов С.С., Белов Ю.С. МОДЕЛЬ ВЫБОРКИ, ИНДЕКСИРОВАНИЯ И ОЧЕРЕДИ ОБЪЕКТОВ В СУБД FOUNDATIONDB // Научное обозрение. Технические науки. 2021. № 2. С. 21-25;URL: https://science-engineering.ru/ru/article/view?id=1341 (дата обращения: 28.07.2026).