

 science-review.ru
science-review.ru
Речь – это неотъемлемая черта каждого человека, которая позволяет ему изучать окружающий мир, делиться с другими людьми своими знаниями и опытом. Благодаря голосовому аппарату человек может осуществлять речевые высказывания в звуковой форме, которые называются «устной речью». Индивидуальное строение голосовых органов характеризуется неповторимыми голосовыми характеристиками для каждого человека.
В связи с развитием информационных технологий и широким распространением средств связи открываются огромные возможности для использования голоса в качестве признака, с помощью которого можно будет устанавливать личность пользователя; помимо этого, голосовая идентификация очень удобна для конечных пользователей и не требует от них наличия сложного технического оборудования.
Средства и технологии голосовой идентификации прекрасно себя чувствуют во многих сферах: электронная коммерция, банковские технологии, криминалистика, безопасность, борьба с терроризмом и др.
В России в 2020 г. было установлено, что с использованием информационно-телекоммуникационных технологий было совершено более 500 тыс. преступлений. Из данных Министерства внутренних дел Российской Федерации следует, что это число на 73,4 % больше, чем было в предыдущем году. Около 410 тыс. преступлений из них были совершены путем кражи или мошенничества [1].
Нельзя забывать, что голос (так же, как и походка, почерк и т.п.) относится к так называемым «поведенческим» или «динамическим» идентификаторам, т.е. голос, под влиянием эмоциональных факторов (настроение человека) или состояния здоровья человека (насморк, бронхит, ангина и т.д.), склонен к серьезным изменениям, что в свою очередь может сильно повлиять на результат идентификации.
Также можно столкнуться и с другими проблемами, если распознавание проводится не в лабораторных условиях. Во-первых, аппаратура, которая записывает и обрабатывает голосовой сигнал, может вызывать искажения. Во-вторых, неизбежно наложение внешних акустических шумов на исходный сигнал, которые могут сильно повлиять на необходимые для идентификации характеристики. Поэтому достичь высокой точности и надежности идентификации – очень сложная задача.
Методы распознавания акустического сигнала бывают дикторозависимые и недикторозависимые [2]. Описываемый в работе метод относится к классу дикторозависимых методов распознавания, который учитывает голосовые признаки диктора. Для исследования голосового сигнала в дикторозависимых методах обычно используют кепстральный анализ [3, 4], который, по сути, является анализом спектра исследуемого сигнала, называемый «кепстром» [5].
Множество работ известных авторов посвящены теории обработки сигнала и методам идентификации диктора. Среди них работы таких авторов, как Матвеев [6], Dehak [7], Раев [8], Пеховский [9] и Симончик [10].
На основе сказанного ранее можно прийти к мнению, что нет сомнений в актуальности автоматизации процесса идентификации пользователя по голосу.
Цель исследования: повышение надежности голосовой идентификации личности в условиях внешнего механического шума.
Материалы и методы исследования
Преобразование Фурье для сигнала используется для получения информации, которая недоступна в исходном виде [11]. Большинство сигналов представляются во временной области, т.е. сигнал представляет зависимость амплитуды от времени. Такое представление не является лучшим, потому что наиболее значимая информация скрыта в частотной области. Преобразование Фурье позволяет перейти от временного представления сигнала к частотному. Временное и частотное измерение представлено на рис. 1.
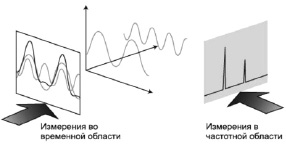
Рис. 1. Измерения сигнала во временной и частотной области
Интегральное преобразования Фурье задается следующей формулой:
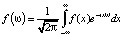 . (1)
. (1)
Цифровая обработка сигналов работает сигналами с дискретными преобразованиями. Поэтому будет удобно представить сигнал в дискретном виде, воспользовавшись преобразованием Фурье:
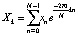 . (2)
. (2)
Необходимо отметить, что существуют недостатки разложения сигналов в ряды Фурье. Поэтому предпочтительнее использовать оконное преобразование Фурье с движущейся по сигналу оконной функцией. Преобразование Фурье выполняется для каждого окна (фрагмента) исходного сигнала, который предварительно был разделен на равные по длительности фрагменты (рис. 2). Тем самым выполняется переход к частотно-временному представлению сигналов, при этом в пределах каждого фрагмента сигнал считается стационарным. Этот способ помогает получать, анализировать и строить в виде спектрограмм динамические спектры и исследовать их поведение во времени. Спектрограмма строится в трех координатах – частота, время и амплитуда.
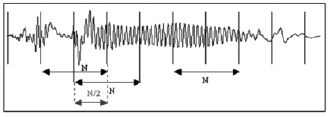
Рис. 2. Разбиение голосового сигнала на фрагменты
Поскольку анализируемый сигнал не является периодическим, приходится на следующем этапе умножать каждый фрагмент на оконную функцию, устраняющую разрывы на границах периодов. В качестве оконной функции мы выбрали функцию Хэмминга:
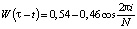 . (3)
. (3)
График, на котором изображена функция Хэмминга, представлен на рис. 3.
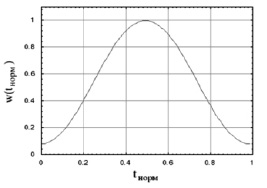
Рис. 3. Функция Хэмминга
Оконное преобразование Фурье (ОПФ) в интегральном виде задается следующей формулой:
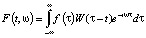 . (4)
. (4)
Формула ОПФ в дискретном виде:
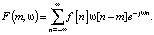 (5)
(5)
Высота звука, которую человек воспринимает, не связана линейно с его частотой, она связана с тембром и уровнем громкости. Поэтому для измерения высоты воспринимаемого звука была придумана величина «мел».
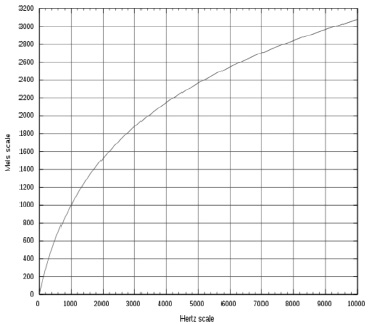
Рис. 4. График зависимости высоты звука в мелах от частоты колебаний
Переход к новой шкале описывается зависимостью
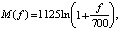 (6)
(6)
График зависимости высоты звука в мелах от частоты колебаний изображен на рис. 4.
Вектор признаков будет состоять из мел-кепстральных коэффициентов. Вычисляются они по формуле
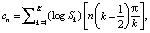 (7)
(7)
Задача классификации решалась методом городских кварталов «манхэттенское расстояние», т.е. вычислением расстояния от вектора признаков анализируемого сигнала p до вектора признаков q вектора шаблона:
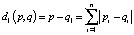 . (8)
. (8)
Результаты исследования и их обсуждение
В ходе работы на языке ????# был создан прототип системы распознавания, интерфейс которой приведен на рис. 5.
Рис. 5. Интерфейс программы идентификации диктора по голосу
Результаты серии экспериментов по определению вероятности правильного распознавания приведены в таблице.
Вероятности правильной идентификации дикторов
|
Количество дикторов |
Количество тестов |
Процент вероятности правильного распознавания, % |
|
2 |
20 |
100 |
|
5 |
50 |
97 |
|
10 |
100 |
92 |
Заключение
В данной работе было проведено изучение использования систем голосовой биометрии в информационных системах. Были рассмотрены алгоритмы кепстрального анализа. Создан прототип системы распознавания, основанной на использовании мел-кепстрального анализа спектра голосового сигнала. Приведены результаты вероятности правильного распознавания.
Библиографическая ссылка
Музафаров Р.Р., Соловьев Н.А. КЕПСТРАЛЬНЫЙ АНАЛИЗ ЗВУКА ДЛЯ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ ПО ГОЛОСУ // Научное обозрение. Технические науки. 2021. № 3. С. 38-42;URL: https://science-engineering.ru/ru/article/view?id=1355 (дата обращения: 26.07.2026).