

 science-review.ru
science-review.ru
Под синтезом речи подразумевается восстановление формы речевого сигнала по его параметрам из текстового представления. Система преобразования текста в речь (TTS) преобразует текст в речь, анализируя и обрабатывая исходные данные с помощью обработки естественного языка (Natural Language Processing (NLP)), затем используя технологию цифровой обработки сигналов (Digital Signal Processing (DSP)) для преобразования этого обработанного текста в синтезированное речевое представление [1]. Большинство из методов синтеза речи представляют собой TTS на уровне предложения, которые могут учитывать информацию временного ряда во всем предложении. Однако необходимо установить инкрементную TTS, которая выполняет синтез в меньших лингвистических единицах, чтобы реализовать синтез с малой задержкой, пригодный для систем одновременного преобразования речи в речь [2]. Рассмотрим некоторые из алгоритмов.
Цель исследования: рассмотреть различные алгоритмы для синтезирования речевого потока. Выявить основные этапы реализации методов. Определить преимущества и недостатки каждого алгоритма.
Формантный синтез
Одним из наиболее широко используемых методов синтеза последнего десятилетия является формантный синтез, который основан на модели речи с фильтром источника. Выделяют две основные структуры: параллельная и каскадная, однако для повышения производительности используют их совместно. Формантный синтез позволяет генерировать бесконечное количество звуков, что делает его более гибким, например, по сравнению с методом конкатенации [3].
Техника синтеза формант – это методика TTS, основанная на правилах. Он производит речевые сегменты путем создания искусственных сигналов на основе набора определенных правил, имитирующих структуру формант и другие спектральные свойства естественной речи. Синтезированная речь генерируется на основе аддитивного синтеза и акустической модели. Основными параметрами акустической модели являются голос, частота, уровни шума и т.д., которые изменяются во времени. Системы на основе формант могут управлять всеми аспектами выходной речи, генерируя широкий спектр эмоций и голоса разного тона с помощью некоторых техник просодического и интонационного моделирования.
Обычно требуется как минимум три форманта для получения членораздельной речи. Пяти формант достаточно, чтобы получить речь высокого качества. Обычно словообразовательный формант моделируется двухполюсным резонатором, позволяющим задавать как частоту форманта, так и ее полосу пропускания [3]. Формант (Q) определяется следующей формулой:
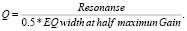
То есть величина «Q» вычисляется путем деления центральной частоты кривой (в Гц) на полуширину кривой эквалайзера (измеренную при половине максимального усиления). Возьмем, например, кривую эквалайзера с центральной частотой 1 кГц и шириной (при половине максимального усиления) 200 Гц. Таким образом, Q будет 1000/100, что равно 10. Точно так же, если бы центральная частота оставалась равной 1 кГц, а ширина была бы всего 50 Гц, Q было бы 40.
К достоинствам данного метода можно отнести высокую разборчивость синтезированной речи даже на высоких скоростях без акустических глюков, а также адаптивность для встраиваемых систем, где память и мощность микропроцессора ограничены. Среди недостатков выделяют сложность разработки правил, определяющих время появления источника и динамические значения всех параметров фильтра даже для простых слов и низкую естественность получаемого речевого потока.
Конкатенативный синтез
Методы конкатенативного синтеза звука (Concatenative sound synthesis (CSS)) используют большую базу данных исходных звуков, сегментированных на единицы (блоки), и алгоритм выбора единиц, который находит последовательность единиц, которая наилучшим образом соответствует звуку или фразе, которые нужно синтезировать, называемой целью.
Целевое расстояние Ct соответствует восприятию подобия блока ui базы данных целевому блоку tτ. Оно задается как сумма p взвешенных функций расстояния отдельных дескрипторов 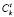 как [4]:
как [4]:
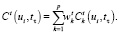
Чтобы способствовать выбору единиц из того же контекста в базе данных, что и в целевой, контекстное расстояние Cx учитывает скользящий контекст в диапазоне r единиц вокруг текущей единицы с весами wj, уменьшающимися с расстоянием j:
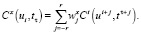
В основном используется Евклидово расстояние, нормированное на стандартное отклонение, а r равно нулю. Некоторым дескрипторам требуются специализированные функции расстояния. Для символьных дескрипторов, например класса фонем, требуется справочная таблица расстояний.
Расстояние конкатенации C выражает нарушение непрерывности, создаваемое конкатенацией единиц ui и uj из базы данных. Он задается взвешенной суммой q функций расстояния конкатенации дескрипторов 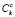
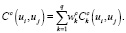
Расстояние зависит от типа блока: объединение основного блока допускает разрывы в высоте звука и энергии, а дополнительный блок – нет. Последовательные блоки в базе данных имеют нулевое расстояние конкатенации. Таким образом, если в базе данных присутствует целая фраза, соответствующая цели, она будет выбрана полностью.
Преимуществом данного метода является высокое качество звука с точки зрения разборчивости. Однако такие системы занимают очень много времени, потому что они требуют огромных баз данных и жестко кодируют комбинацию для формирования этих слов и результирующая речь может казаться менее естественной и безэмоциональной.
Методы PSOLA
Метод PSOLA (Pitch Synchronous Overlap Add) изначально был разработан компанией France Telecom (CNET). Данный метод хотя и не является методом синтеза, но предоставляет возможность плавно объединять предварительно записанные речевые образцы и обеспечивать контроль высоты тона и длительности, поэтому он используется в некоторых коммерческих системах синтеза речи, таких как ProVerbe и HADIFIX.
Базовый алгоритм состоит из трех шагов [5]:
1. Этап анализа, на котором исходный речевой сигнал сначала разделяется на отдельные, но часто перекрывающиеся сигналы краткосрочного анализа.
2. Преобразование каждого сигнала анализа в сигнал синтеза.
3. Этап синтеза, на котором эти сегменты рекомбинируются посредством перекрывающегося добавления. Кратковременные сигналы xm(n) получаются из цифрового речевого сигнала x(n) путем умножения сигнала на последовательность сегментов анализа с синхронизацией по высоте тона hm(n):
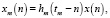
где m – индекс кратковременного сигнала,
tm – последовательные моменты, называемые шагами.
Эти метки устанавливаются с синхронной частотой тона для вокализованных частей сигнала и с постоянной скоростью для невокализованных частей. Используемая длина сегмента пропорциональна локальному периоду основного тона, а коэффициент сегмента обычно составляет от 2 до 4. Маркеры основного сегмента определяются либо вручную, либо автоматически некоторыми методами оценки. Рекомбинация сегментов на этапе синтеза выполняется после определения новой последовательности меток основного тона.
TD-PSOLA имеет следующие недостатки: оптимальная разметка шага не является полностью автоматической, а шаг, фаза и рассогласование спектральных амплитуд не позволяют адекватно сглаживать конкатенации. Более того, он предлагает несколько возможностей сжатия базы данных (скорость хранения 80000 бит/с может быть достигнута с помощью кодировщика DPCM с нулевым отводом). Однако он обеспечивает хорошее качество сегментов, а его вычислительная нагрузка очень низка: 7 операций на образец [6].
Методы, основанные на линейном прогнозировании
Способы линейного прогнозирования изначально разработаны для систем кодирования речи, но могут также использоваться в синтезе речи. Фактически первые синтезаторы речи были разработаны из кодировщиков речи. Как и формантный синтез, базовый метод линейного прогнозирования (Linear Predictive Coding (LPC)) основан на модели речи с фильтром источника. Коэффициенты цифрового фильтра оцениваются автоматически из кадра естественной речи.
Основная идея линейного прогнозирования заключается в возможности аппроксимировать речевую выборку y(n) или предсказать ее из набора предыдущих p выборок от y(n – 1) до y(nk) линейной комбинацией с малой погрешностью e(n), называемой остаточным сигналом. Тогда получим следующие выражения [5]:
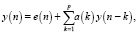
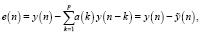
где 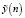 – предсказанное значение,
– предсказанное значение,
p – порядок линейного предсказателя,
a(k) – коэффициент линейного предсказания, образуемый путем минимизации суммы квадратов отклонений.
Для вычисления этих коэффициентов обычно используются два метода: метод ковариации и метод автокорреляции, однако только с помощью метода автокорреляции фильтр гарантированно будет стабильным.
На этапе синтеза используемое возбуждение аппроксимируется последовательностью импульсов для звонких звуков и случайным шумом для невокализованных звуков. Затем для обработки полученного сигнала используется цифровой фильтр, коэффициенты которого равны a(k). Порядок фильтра обычно составляет от 10 до 12 при частоте дискретизации 8 кГц, однако если требуется получить более высокое качество с частотой дискретизации 22 кГц, то используется порядок от 20 до 24. Коэффициенты обычно обновляются каждые 5–10 мс.
Главный недостаток обычного метода линейного прогнозирования состоит в том, что он представляет собой многополюсную модель, а это означает, что фонемы, содержащие антиформанты, такие как носовые и назализованные гласные, моделируются плохо. Качество также низкое с короткими взрывными согласными (плозивы, эксплозивные, чистые смычные), потому что события временного масштаба могут быть короче, чем размер кадра, используемый для анализа. Из-за этих недостатков качество синтеза речи стандартным методом LPC обычно считается плохим, но с некоторыми модификациями и расширениями базовой модели качество может быть улучшено [5, 6].
Искаженное линейное прогнозирование (Warped Linear Prediction (WLP)) использует преимущества человеческого слуха, и необходимый порядок фильтрации затем значительно снижается с порядков 20–24 до 10–14 с частотой дискретизации 22 кГц. Основная идея заключается в том, что единичные задержки в цифровом фильтре заменяются следующими всепроходными участками:
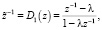
где λ – параметр деформации между -1 и 1,
D1(z) – элемент задержки деформации, а со шкалой Барка это l = 0,63 с частотой дискретизации 22 кГц.
WLP обеспечивает лучшее качество на низких частотах и хуже работает на высоких частотах.
Синусоидальные модели
Синусоидальные модели базируются на теории, что речь может быть представлена в виде суммы синусоидальных волн с амплитудами и частотами, которые изменяются во времени. В базовой модели речевой поток s(n) представляется в виде суммы небольшого количества L синусоид [5]:
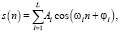
где Al(n) и φl(n) представляют собой амплитуду и фазу синусоидальных составляющих, связанных с частотной дорожкой ωl. Для поиска параметров Al(n) и φl(n), вычисляется дискретное преобразование Фурье сегментных сигнальных кадров, и для каждого кадра выбираются экстремумы спектральной величины. Базовая модель, известная как модель Маколея/Кватиери, имеет некоторые модификации, такие как модели ABS/OLA (анализ путем синтеза/добавления перекрытия) и модели гибридного/синусоидального шума.
Синусоидальные модели хорошо подходят для представления гласных и звонких согласных, но плохо работают для представления глухих звуков.
Заключение
Синтез текста в речь – это быстро развивающийся аспект компьютерных технологий, который играет все более важную роль в том, как мы взаимодействуем с системой и интерфейсами на различных платформах. Формантный и конкатенативный методы наиболее часто используются в современных системах синтеза речи. На протяжении длительного времени преобладал формантный синтез, но сегодня все более популярным становится метод конкатенации. В настоящее время существует несколько направлений, основанных на модернизации конкатенативного синтеза текста в речь. Одним из основных направлений является инвентаризация логических единиц.
До сих пор из-за соображений вычислительной сложности и требований к памяти в хранилищах размещалось не более пары токенов для каждой необходимой единицы. Далее, в зависимости от контекста, токены изменялись по таким параметрам, как высота амплитуда и длительность. Основная задача заключалась в оптимальном подборе токенов.
Не так давно стало популярным повышение количества хранимых токенов, части которых могут появляться в различных контекстах, с различным шагом и продолжительностью. Это отрицательно сказывается на работе, так как требуется гораздо больше объема памяти и большего объема вычислений для поиска в большом инвентаре. Однако благодаря развитию современных процессоров доступная память и вычислительная скорость расширяются очень быстро и становятся вполне доступными [7].
Библиографическая ссылка
Хлопенкова А.Ю., Гришунов С.С., Белов Ю.С. АЛГОРИТМЫ ПРЕОБРАЗОВАНИЯ ТЕКСТА В РЕЧЬ НА ОСНОВЕ РАЗЛИЧНЫХ ФОРМ СИНТЕЗА // Научное обозрение. Технические науки. 2021. № 5. С. 20-23;URL: https://science-engineering.ru/ru/article/view?id=1371 (дата обращения: 21.07.2026).