

 science-review.ru
science-review.ru
Текст можно рассматривать как сочетание темы и стиля. Тема определяет содержание текста, а стиль отражает особый способ автора манипулировать словами. Основная идея этой статьи состоит в том, чтобы изучить отдельное представление темы и представление стиля для данного текста. В этом исследовании предлагается многозадачный подход для совместной оптимизации основной задачи – атрибуции авторства и вспомогательной задачи – аппроксимации темы.
В частности, задача аппроксимации темы состоит в том, чтобы создать представление темы для аппроксимации распределения темы текста. Распределение тем определяется независимыми от задачи моделями, которые обучаются на внешнем корпусе текстов [1]. Таким образом, наша структура обеспечивает контроль для разделения стилей тем и не требует человеческого вмешательства для аннотирования данных.
Цель исследования – изучить способы определения авторства и аппроксимации темы текста.
Механизмы конкурентного внимания и ограничения разделения-восстановления
Часть разделения стиля темы предназначена для создания распределенных представлений темы и стиля соответственно. Стилевое представление используется для основной задачи: установления авторства, а тематическое – для вспомогательной задачи: аппроксимации темы.
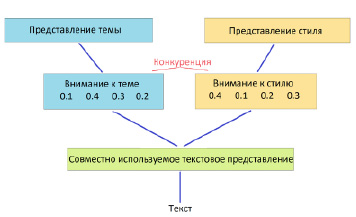
Рис. 1. Механизм конкурентного внимания
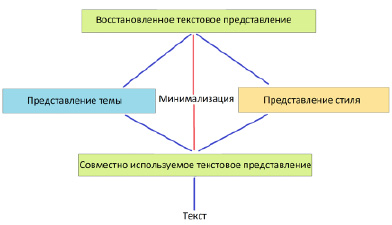
Рис. 2. Ограничение разделения-восстановления
Для достижения поставленных целей предлагаются две идеи: механизм конкурентного внимания и ограничение разделения-восстановления. Рисунки 1 и 2 иллюстрируют две идеи.
Конкурентное внимание – это расширение механизма внимания, который учится присваивать разные веса разным токенам. Здесь мы используем внимание, чтобы выделить общее текстовое представление, чтобы получить отдельные представления для темы и стиля. Если слову уделяется большое внимание для одной задачи, ему будет отведено низкое внимание для другой задачи. Другими словами, два представления конкурируют за внимание каждого слова.
Ограничение разделения-восстановления вводит затраты на восстановление в дополнение к оптимизации двух вышеупомянутых задач. Ожидается, что представления темы и стиля могут реконструировать представление текста, чтобы сохранить исходное значение.
Конкурентное внимание для разделения темы и стиля
Рекуррентная нейронная сеть (RNN) подходит для обработки последовательных данных и для захвата долгосрочных зависимостей. RNN используется в качестве базовой архитектуры в этой работе [2].
1) LSTM на основе внимания
Слова текста преобразуются во вложения слов, которые представляют собой плотные векторы действительных значений. Входной текст может быть представлен в виде матрицы
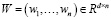 ,
,
где d – размер встраивания, а n – количество токенов в тексте. В качестве основной ячейки памяти мы используем долговременную кратковременную память (LSTM). На временном шаге t LSTM берет скрытое состояние с предыдущего временного шага и встраивание слова с текущего шага в качестве входных данных и создает новое скрытое состояние [3].
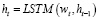 (1)
(1)
Вся последовательность создает n скрытых состояний, представленных как H = (h1,…,hn). Сначала мы получаем ui, скрытое представление hi, через многослойный персептрон (MLP).
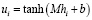 (2)
(2)
Затем вводится контекстный вектор uc для вычисления весов токенов.
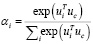 , (3)
, (3)
где uc является общим для всех текстов и случайным образом инициируется и обновляется во время обучения.
При векторе внимания α = (α1,…,αn) окончательное представление текста является взвешенной суммой скрытых состояний [4],
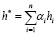 (4)
(4)
2) Конкурентное внимание
Стандартный механизм внимания подходит для получения единичного представления текста [5]. В нашем сценарии мы хотим получить два представления для темы и стиля соответственно. Наше решение состоит в том, чтобы использовать различное внимание к общему представлению, чтобы получить представление для конкретной задачи. Мы вводим механизм конкурентного внимания, чтобы усилить конкуренцию между двумя представлениями.
Учитывая скрытые состояния H = (h1,…,hn), конкурентные внимания представляют собой два вектора внимания α = (α1,…,αn) и β = (β1,…,βn) для вычисления представлений для задачи T1 и задачи T2. Сначала мы вычисляем α в соответствии со стандартным механизмом внимания [6]. Sα – отсортированные m (1≤m≤n) различных значений α, Rα = (r1,…,rn) – ранг αi среди m значений. Для 1≤i≤n, пусть
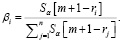
Окончательные представления для T1 и T2:
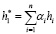 ,
,
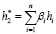 .
.
Ограничение разделения-восстановления
Теперь у нас есть отдельные представления по теме и стилю. Мы надеемся, что разделение не изменит смысла. Поэтому мы используем ограничение разделения-восстановления и ожидаем, что исходное представление может быть восстановлено с помощью представления темы и представления стиля [7].
1) Оригинальное представление
Объединяем скрытые представления H = (h1,…,hn), чтобы получить вектор h1 размерности d×n в качестве исходного представления текста.
2) Скрытые представления
Мы используем представление темы 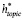 и представление стиля
и представление стиля 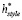 , созданное конкурентным вниманием, в качестве скрытых представлений.
, созданное конкурентным вниманием, в качестве скрытых представлений.
3) Реконструированное представление 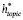 и
и 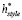 объединяются, а затем сопоставляются с вектором d×n, чтобы получить реконструированное представление hr, т. е.
объединяются, а затем сопоставляются с вектором d×n, чтобы получить реконструированное представление hr, т. е. 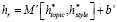 .
.
4) Потеря восстановления
Сначала мы вычисляем манхэттенское расстояние D между hr и h0. Затем вычисляем потери
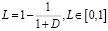 .
.
Многозадачное обучение для установления авторства
Мы формулируем атрибуцию авторства с помощью многозадачного подхода к обучению на основе представления темы 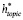 и представления стиля
и представления стиля 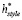 .
.
1) Основная задача: установление авторства
Мы используем 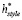 для указания авторства.
для указания авторства. 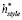 подключается к слою softmax, чтобы получить распределение по кандидатам в авторы. Перекрестная энтропия используется в качестве функции потерь для классификации.
подключается к слою softmax, чтобы получить распределение по кандидатам в авторы. Перекрестная энтропия используется в качестве функции потерь для классификации.
2) Вспомогательное задание: приближение темы
Учитывая текст, мы используем предварительно обученную модель, чтобы вывести его распределение тем θ по K темам. Тематическая модель основана на модели LDA, но с фоновой моделью для захвата общих слов, так что извлеченные темы обычно присваивают более высокие вероятности содержательным словам.
Полносвязная сеть используется для сопоставления 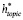 с вектором измерения K, а затем этот вектор нормализуется с помощью слоя softmax, чтобы получить приблизительное распределение тем θ′. Функция потерь для этой задачи представляет собой перекрестную энтропию между θ и θ′.
с вектором измерения K, а затем этот вектор нормализуется с помощью слоя softmax, чтобы получить приблизительное распределение тем θ′. Функция потерь для этой задачи представляет собой перекрестную энтропию между θ и θ′.
Практическая оценка предложенной модели
Эксперимент проводится на наборе данных IMDb62, который содержит 62 000 рецензий на фильмы от 62 авторов, у каждого из которых по 1000 рецензий. Набор случайным образом разделён на обучающую выборку (80 %) и тестовую выборку (20 %).
Для проверки способности противостоять влиянию тем было выбрано подмножество экземпляров из тестового набора, обозначенное как IMDb62-Hard. Специфика набора заключается в том, что у каждого автора есть не более одной рецензии на один фильм. Обзоры в тестовом наборе были выбраны таким образом, чтобы прокомментированные фильмы появились и в обучающем наборе, но были прокомментированы другими пользователями, чтобы этот тестовый набор данных был более сложным по сравнению со всем тестом. Таким образом, у нас есть 6000 тестовых обзоров.
Как видно из таблицы 1, улучшения на IMDB62 и IMDB62-Hard небольшие. Основная причина состоит в том, что все тексты имеют сходную тематику. Большинство обзоров концентрируются на таких аспектах, как актеры/актрисы/режиссеры, сюжеты, музыка и личные чувства. Это не очень хорошая межтематическая настройка. Помимо языковых стилей, личные интересы авторов, например особые предпочтения в отношении некоторых режиссеров или жанров фильмов, служат сигналами для их различения.
Определение темы
В табл. 2 показаны наиболее вероятные темы, основные слова темы и внимание к теме на уровне токенов для образца текста в IMDb62. Текст имеет высокие вероятности по теме 96 (P = 0,46), теме 18 (P = 0,29) и теме 10 (P = 0,1) среди изученных тематических моделей. Под словами темы показаны весовые коэффициенты внимания к теме на токенах, основанные на механизме конкурентного внимания.
Из таблицы видно, что слова с высоким весом внимания темы также имеют более высокие вероятности в показанных языковых моделях темы, таких как шоу, музыка, телевидение. Это указывает на то, что аппроксимация темы успешно направляет представление темы к распределению темы текста.
С другой стороны, мы видим токены с малым весом внимания к теме. Многие из них являются общеупотребительными служебными словами. Некоторые распространенные глаголы, такие как like, be и местоимения, также имеют низкий вес внимания к теме. Эти слова не зависят от темы, но могут в некоторой степени отражать личный стиль.
Таблица 1
Сравнение точности определения авторства различных моделей
|
Модель |
IMDb62 |
IMDb62-Hard |
|
CNN-CharNgrams [8] |
90,66 % |
90,59 % |
|
CNN-WordPOS [9] |
90,84 % |
90,72 % |
|
Конкурентное внимание |
91,35 % |
91,09 % |
|
Конкурентное внимание + разделение-восстановление |
91,81 % |
91,51 % |
Таблица 2
Наиболее вероятные темы и слова, характерные для данной темы
|
Тема 96 (P = 0,46) |
Тема 18 (P = 0,29) |
Тема 10 (P = 0,10) |
Тема 103 (P = 0,023) |
||||
|
film |
0,017 |
music |
0,014 |
new |
0,005 |
show |
0,010 |
|
series |
0,012 |
album |
0,013 |
one |
0,005 |
time |
0,008 |
|
episode |
0,006 |
band |
0,011 |
would |
0,004 |
channel |
0,006 |
|
story |
0,006 |
film |
0,010 |
later |
0,004 |
soap |
0,006 |
|
show |
0,005 |
song |
0,008 |
said |
0,003 |
new |
0,005 |
Заключение
В этой статье представлен многозадачный подход к обучению для разделения стилей темы для определения авторства, предложены механизмы конкурентного внимания и ограничение разделения-восстановления для разделения темы и стиля. Ожидается, что метод многозадачного обучения, основанный на аппроксимации темы, будет особенно эффективен в межтематических условиях, однако он позволяет лучше определять авторство даже на специфическом наборе данных, с незначительной вариативностью тем. Предложенная модель так же способна эффективно различать формальный и неформальный стили речи, что способствует более точному определению темы текста.
Библиографическая ссылка
Батурин М.М., Белов Ю.С. ПРИМЕНЕНИЕ МНОГОЗАДАЧНОГО ОБУЧЕНИЯ ДЛЯ ОПРЕДЕЛЕНИЯ АВТОРСТВА ТЕКСТА НА ОСНОВЕ МЕХАНИЗМА КОНКУРЕНТНОГО ВНИМАНИЯ // Научное обозрение. Технические науки. 2022. № 3. С. 5-9;URL: https://science-engineering.ru/ru/article/view?id=1392 (дата обращения: 30.07.2026).
DOI: https://doi.org/10.17513/srts.1392