

 science-review.ru
science-review.ru
В настоящее время нейронные сети стремительно развиваются, расширяя свое влияние практически на все сферы человеческой деятельности, предлагая различные решения для многочисленного спектра задач. Одной из таких задач является генерация изображений – сфера искусственного интеллекта, в рамках которой компьютеры обучаются интерпретировать визуальный мир. Дополнительным параметром в данной задаче является использование технологии генерации изображения по тексту (Text-To-Image). Ввиду этого применение генеративно-состязательных сетей (GAN) позволит успешно и стабильно решать данную задачу.
Цель исследования – исследовать архитектуру, концепции обучения и принципы работы генеративно-состязательных сетей для генерации изображения по тексту (Text-To-Image).
Общая информация о генеративно-состязательных сетях. Генеративно-состязательные сети (GAN) – это алгоритмические архитектуры, которые используют две нейронные сети, противопоставляя одну другой для создания новых синтетических экземпляров данных, которые можно принять за реальные данные [1]. Они широко используются в таких сферах, как: генерации изображений, генерации видео и генерации голоса.
Потенциал генеративно-состязательных сетей (GANs) огромен, они могут научиться имитировать любое распределение данных благодаря самому процессу состязания одной сети с другой. То есть генеративно-состязательные сети можно научить создавать изображения, максимально приближенные к реальности.
Общие принципы обучения моделей генерации изображений (T2I). Любые модели, используемые для генерации изображений по тексту, обучаются на больших наборах данных, представляющих собой наборы пар (текст, изображение), то есть изображения с текстовыми подписями (описанием) [2].
Самым распространенным набором данных, используемым для обучения моделей генерации изображений, является упомянутый ранее набор COCO (Common Objects in Context), состоящий из 123 000 изображений различных объектов, с пятью текстовыми описаниями к каждому изображению [3].
Также в области генерации изображений были разработаны метрики количественной оценки (например, R-точность (R-precision), визуально-семантическое сходство и семантическая точность результирующего объекта), которые были введены специально для оценки качества моделей генерации текста в изображение, а именно: T2I – Text To Image [4] (рис. 1).
Принцип работы и обучения генеративно-состязательных сетей. Рассмотрим детально генеративно-состязательные сети. Они состоят из двух нейронных сетей: генераторной сети G(z) с шумом z ~ pz, выбранным из предыдущего распределения шума, и дискриминаторной сети D(x), где x ~ pdata реальные изображения, а x ~ pg – сгенерированные изображения соответственно [5].
Обучение представляет собой взаимодействие двух нейронных сетей, в которой одна нейронная сеть, называемая генератором, генерирует новые экземпляры данных, а другая, дискриминатор, оценивает их на подлинность. Другими словами, дискриминатор решает, принадлежит ли каждый экземпляр данных, которые он просматривает, фактическому набору обучающих данных или нет (рис. 2).
Обучение можно определить как минимаксную игру двух игроков (правило принятия решений, используемое в теории игр) с функцией V (D, G), где дискриминатор D(x) обучается максимизировать логарифмическую вероятность, присваивая ей правильный класс, в то время как генератор G(z) обучается минимизировать вероятность того, что дискриминатор log(1 − D(G(z)) классифицирует его как фальшивый [6]:
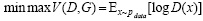
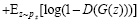
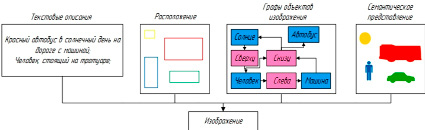
Рис. 1. Виды аннотаций, используемых для генерации изображений по тексту
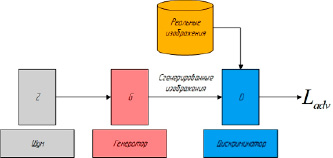
Рис. 2. Принцип обучения генеративно-состязательной сети
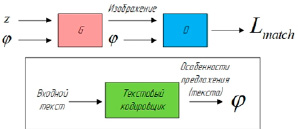
Рис. 3. Принцип работы технологии генерации изображения по тексту в генеративно-состязательных сетях
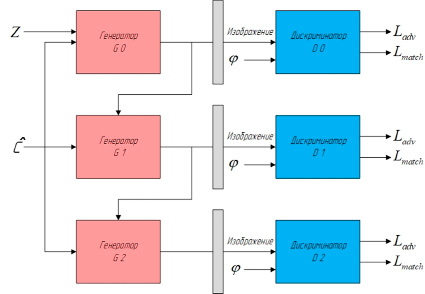
Рис. 4. Архитектура генеративно-состязательной сети StackGAN++
Использование технологии генерации изображения по тексту (Text To Image). Первый подход T2I обусловливает процесс генерации анализа всего предложения, полученного из предварительно обученного текстового кодировщика.
Дискриминатор обучен различать реальные и сгенерированные пары «изображение – текст». Следовательно, модель T2I является естественным расширением генеративно-состязательной сети в том смысле, что условие на метке класса Y просто заменяется текстовым вложением φ (рис. 3).
В глубокой сверточной генеративно-состязательной сети (GAN-INT-CLS) в качестве входных данных для дискриминатора используются три разные пары:
- реальное изображение с совпадающим текстом;
- сгенерированное изображение с соответствующим текстом;
- реальное изображение с несовпадающим текстом.
Такой подход заставляет и генератор, и дискриминатор не только фокусироваться на реалистичных изображениях, но и сравнивать их с входным текстом [7].
Однако ранние версии GAN-INT-CLS могли генерировать только изображения с низким разрешением 64 × 64 пикселя.
Чтобы модели, основанные на генеративно-состязательных сетях, могли генерировать изображения с более высоким разрешением, необходимо использовать обновленную архитектуру, включающую в себя несколько объединенных генераторов – StackGAN.
В StackGAN на первом этапе генерируется грубое изображение размером 64×64 пикселя с учетом вектора случайного шума и вектора обработки текста. Это исходное изображение и текст поступают во второй генератор, который выводит изображение уже размером 256 × 256 пикселей [8]. На обоих этапах дискриминатор обучается различать совпадающие и не совпадающие пары «изображение – текст».
StackGAN++ еще больше улучшил архитектуру с помощью сквозной структуры, в которой три генератора и дискриминатора совместно обучаются для одновременной аппроксимации многомасштабных, условных и безусловных распределений изображений [9] (рис. 4).
Применение генеративно-состязательных сетей для генерации изображения по тексту. Рассмотрим пример, в котором необходимо сгенерировать написанные от руки цифры, подобные тем, которые можно найти в открытом наборе данных. Цель дискриминатора при отображении экземпляра из истинного набора данных состоит в том, чтобы распознать те, которые являются подлинными (рис. 5).
Тем временем генератор создает новые синтетические изображения, которые он передает дискриминатору. Это делается с расчетом на то, что они тоже будут считаться подлинными, даже если они – сгенерированные нейронной сетью поддельные. Цель генератора – генерировать максимально приближенные к реальности рукописные цифры. Цель дискриминатора – идентифицировать изображения, поступающие от генератора, как фальшивые или же попросту неудачные, то есть некачественные [10] (рис. 6).
Сам же алгоритм данного процесса заключается в следующем:
1. Генератор принимает случайные числа и возвращает изображение.
2. Сгенерированное изображение подается в дискриминатор вместе с потоком изображений, взятых из фактического, достоверного набора данных.
3. Дискриминатор принимает как настоящие, так и поддельные изображения и возвращает число от 0 до 1, где 1 представляет собой прогноз подлинности, а 0 представляет подделку.
Вследствие этого данная модель обучается распознавать правдоподобные изображения, благодаря чему она сможет уже сама синтезировать необходимые изображения такого типа, при этом максимально приближенные к настоящим.
Такие результаты обеспечиваются за счет долгого и последовательного обучения нейронной сети, что отчасти является недостатком стандартных генеративно-состязательных сетей, поскольку процедура состязательного обучения внутри таких моделей проблематично масштабируется для моделирования сложных мультимодальных распределений.
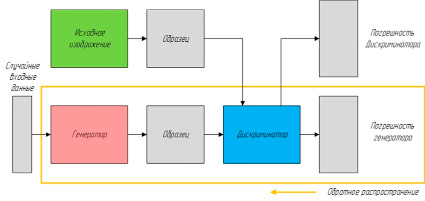
Рис. 5. Принцип работы генеративно-состязательной сети для генерации изображений
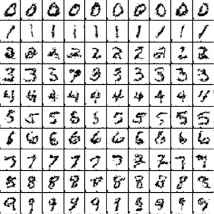
Рис. 6. Пример сгенерированных изображений цифр при помощи генеративно-состязательной сети
Заключение
Таким образом, генеративно-состязательные сети являются хорошим подходом к решению задач генерации изображений по тексту, подразумевающих использование технологии Text To Image, обеспечивая при этом достойные результаты в виде сгенерированных изображений, зачастую достаточно точно отображающих объекты, упомянутые текстовым описанием на этапе ввода данных.
Несмотря на внушительные результаты, большинство моделей, основанных на генеративно-состязательных нейронных сетях, зачастую имеют небольшие затруднения как в процессе непосредственного обучения, так и в процессе последующего использования – генерации изображений, ввиду ограниченного разнообразия выборок, что зачастую приводит к большим временным затратам, а в рамках масштабных нейронных сетей, которые обучаются на сотнях миллионов входных изображений, это приводит к замедлению процесса создания конечной модели. Однако данные недостатки компенсируются точностью и качеством результирующих изображений, что подтверждает обоснованность их применения для такого рода задач.
Библиографическая ссылка
Левин А.О., Белов Ю.С. ИСПОЛЬЗОВАНИЕ ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ ДЛЯ ГЕНЕРАЦИИ ИЗОБРАЖЕНИЙ ПО ТЕКСТУ // Научное обозрение. Технические науки. 2023. № 2. С. 11-15;URL: https://science-engineering.ru/ru/article/view?id=1427 (дата обращения: 27.07.2026).
DOI: https://doi.org/10.17513/srts.1427