

 science-review.ru
science-review.ru
Все созданные на данный момент модели генерации музыки можно классифицировать в зависимости от вида использованного алгоритма на четыре вида: основанные на правилах, использующих марковскую модель, работающие на алгоритмах глубокого обучения и применяющие эволюционные вычисления. Наиболее распространенными из них являются модели, в основе которых лежат алгоритмы глубокого обучения.
Цель исследования– рассмотреть модели глубокого обучения для генерации музыки, такие как рекуррентные нейронные сети, генеративные состязательные сети, вариационнные автоэнкодеры и трансформеры.
Общая структура модели
Генерация контента– это расширенная область глубокого обучения. Благодаря достижениям Google black и CTRL в области создания музыки, глубокое обучение как метод создания музыки привлекает все большее внимание. В отличие от систем музыкальной генерации, которые оперируют грамматикой или правилами, системы, использующие глубокое обучение, способны анализировать распределение и актуальность сэмплов из различных музыкальных корпусов и создавать музыку в стиле исследуемого массива путем прогнозирования или классификации [1].
Рекуррентные нейронные сети
Рекуррентные нейронные сети (RNN) представляют собой класс нейронных сетей, предназначенных для анализа временных рядов, что делает их удобными для работы с музыкальными данными. Однако проблема длительных временных зависимостей остается актуальной для RNN из-за проблемы градиентного исчезновения или взрыва, которая возникает при обучении на длинных временных последовательностях. LSTM, как вариант RNN, эффективно решает проблему длительной временной зависимости RNN, вводя состояния ячеек и используя три типа элементов управления, а именно входные элементы, элементы забывания и выходные элементы, предназначенные для хранения информации и управления ею [2].
Google Brain разработала MelodyRNN (рис. 1), где использовались lookback RNN и attention RNN для повышения способности RNN к запоминанию структур в длинных последовательностях. Кирти и его коллеги внедрили механизм внимания и использовали метод отсева для снижения переобучения при создании джазовой музыки [3]. Rl Tuner использует сеть RNN для предоставления частичных значений вознаграждения для модели обучения с подкреплением. Нейронная сеть Anticipation-RNN для генерации мелодий интерактивных припевов в стиле Баха. Макрис и соавт. разработали индивидуальные сети LSTM для различных видов барабанов, при этом сеть прямой связи (FF) играла роль условного уровня [4]. StructureNet создает базовую монофоническую сопровождающую музыку, используя сети LSTM.
Что касается генерации аранжировок, Folk-RNN впервые применила LSTM для создания музыкальных последовательностей, представленных в формате ABC для создания народной музыки. DeepBach использует Bi-LSTM для создания хоровой музыки в стиле Баха, учитывая двунаправленный поток времени: одно направление учитывает прошлое, а другое– будущее. XiaoIce Band предлагает сквозную китайскую многодорожечную платформу для генерации поп-музыки, которая использует сеть GRU для обработки низкоразмерных аккордов и получение скрытых состояний с помощью кодеров и декодеров. Amadeus применяет явный подход к кодированию длительности, представляя несколько аудиопотоков в виде длительности нот и используя механизм вознаграждения RL для улучшения структуры создаваемой музыки. JamBot использует LSTM сеть аккордов для предсказания последовательностей аккордов и полифоническую LSTM сеть для генерации полифонической музыки на основе этих предсказанных последовательностей аккордов [5].
PerformanceRNN преобразует MIDI-файл живой фортепианной пьесы в музыкальное представление нескольких one-hot векторов с 413 измерениями и определяет временной «шаг» фиксированного размера (10 мс) вместо значения времени ноты. PerformanceNet– это первая попытка преобразования партитуры в аудио с использованием полностью сверточной нейронной сети с символическим представлением музыки в качестве входных данных и звуковым представлением в качестве выходных данных [6].
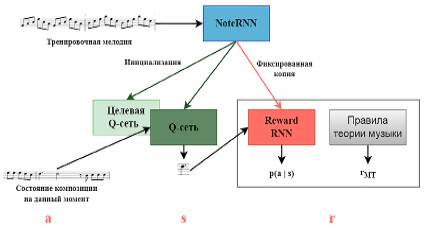
Рис. 1. Архитектура модели MelodyRNN
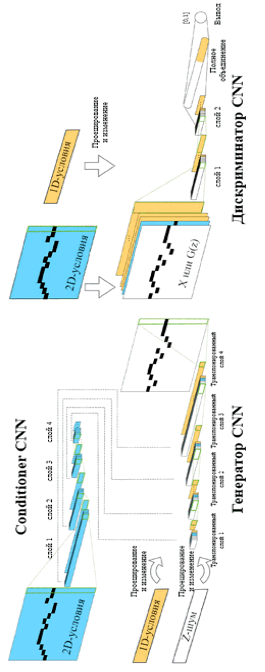
Рис. 2. Системная схема модели MidiNet для генерации музыки в символьном представлении
Генеративные состязательные сети
Генеративные состязательные сети (GAN) работают по принципу соревнования между двумя нейронными сетями: генератором и дискриминатором. Генератор создает новые данные из случайного шума или других данных. Он стремится создать данные, которые похожи на обучающие. Дискриминатор принимает как настоящие обучающие данные, так и данные, созданные генератором, и пытается отличить их друг от друга.
C-RNN-GAN использует LSTM сети для создания музыкальных мелодий, однако он не имеет механизма для создания музыки с учетом определенного начального условия. MidiNet (рис. 2) улучшает метод, вставляя информацию о мелодии и аккорде, сгенерированных на предыдущем этапе, в качестве условного механизма на среднем уровне свертки генератора для ограничения генерации типов нот. JazzGAN разработал модель GAN для монофонической джазовой музыки, используя LSTM для музыкальной импровизации на основе последовательности аккордов. SSMGAN применил модель GAN для создания самоподобной матрицы (SSM) для отражения музыкальных самоповторов, которая затем была подана на сеть LSTM для генерации мелодий. Для генерации мелодии из текстов песен был разработан условный LSTM-GAN. Он содержит генератор LSTM и дискриминатор LSTM, оба с текстами песен в качестве условных входных данных.
Для генерации аранжировки MusGAN предложил модель GAN с тремя типами генераторов для построения корреляций между несколькими дорожками. BinaryMuseGAN усовершенствовал вышеупомянутый метод, введя бинарные нейроны (BN) в качестве входных данных для генератора.
Лян и соавт. провели исследования, в котором попытались воссоздать сианьскую барабанную музыку, обучив генеративную сеть на правилах теории музыки и характеристиках китайской народной музыки [7].
Когда речь идет о передаче стиля и создании звука, CycleGAN применяет функцию потери стиля для изменений и функцию потери контента для сохранения согласованности контента [8]. CycleBEGAN использует сеть BEGAN для стабилизации процесса обучения, а также вводит переходные соединения для улучшения четкости мелодии и текстов песен, а также рекурсивные слои для повышения точности высоты тона для достижения преобразования мужского и женского голоса. Кроме того, Джин и др. использовали сеть LSTM в качестве генератора, добавив музыкальные правила в качестве функции вознаграждения при обучении с подкреплением в управляющую сеть [9]. В области генерации звука WaveGAN был первым, кто попытался использовать GAN для создания аудиосигналов в их необработанном виде, а GANSynth усовершенствовал этот подход, генерируя всю последовательность параллельно.
Вариационный автоэнкодер
Вариационный автоэнкодер (VAE)– это алгоритм сжатия для кодеров и декодеров, который способен анализировать и генерировать такую информацию, как динамику высоты тона и инструментовку в полифонической музыке.
Примерами таких моделей являются MIDI-VAE и MusicVAE (рис. 3). MIDI-VAE использует три пары кодеров/декодеров, которые вместе используют латентное пространство для автоматического восстановления высоты тона, интенсивности и инструментовки музыкальной композиции, с целью изменения музыкального стиля. MusicVAE использует иерархический декодер для улучшения моделирования последовательностей с долговременной структурой, используя двунаправленный RNN в качестве кодера. Вэй и соавт. не применяли сквозной подход к изучению иерархических представлений, а вместо этого представили новую модель, основанную на EC2-VAE [10]. Дубнов и соавт. разработали vanilla polyphonic VAE, используя только линейные слои, чтобы изучить скрытое представление музыкальной поверхности [11].
MG-VAE– первое исследование, где были использованы глубокие генеративные модели и методы состязательного обучения для создания восточной популярной и фолк-музыки [12].
MahlerNet построил условный VAE длямоделирования распределения латентных состояний. Две двунаправленные сети RNN образуют кодер, а декодер выводит длительность, высоту звука и инструмент [13]. MIDI-Sandwich2 представляет иерархическую мультимодальную сеть, порожденную слиянием VAE (MFG-VAE), основанную на RNN. MusAE впервые применил состязательные автоэнкодеры для генерации музыки.
Трансформер
Основная идея этой архитектуры заключается в использовании механизма внимания для указания корреляций между входными данными.
Музыкальный трансформер существенно снижает пространственную сложность промежуточных векторов, представляющих относительное положение в порядке очередности длины, что делает его применимым для фортепианных музыкальных композиций.
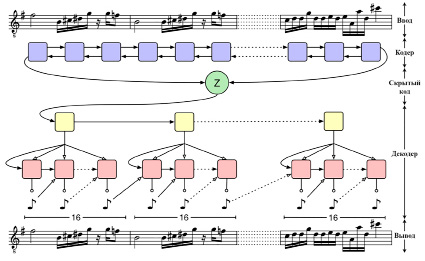
Рис. 3. Схема иерархической рекуррентной вариационной модели автоэнкодера MusicVAE
MuseNet использовала ту же сеть, что и GPT-2, которая обучается с использованием пересчитанного и оптимизированного ядра трансформера для генерации четырехминутной музыкальной композиции, состоящей из десяти различных инструментов. На рис. 4 показана блок-схема этого трансформаторного самокодера [5].
Цао с соавт. предложили метод, основанный на трансформере, для генерации высококачественной мультиинструментальной музыки из входных данных аккордовой последовательности [14]. Muse Morphose предлагает соединить воедино трансформер и вариационный автоэнкодер для того, чтобы добиться передачи стиля длинных пьес для фортепиано поп-музыки, где могут быть указаны различные атрибуты композиции. Transformer VAE объединяет трансформер с VAE, эффективно устраняя ограничения VAE в обработке структур временных рядов и невыясненной природы скрытых состояний трансформера. Чой и соавт. аналогичным образом использовали трансформер (декодер) для получения глобального представления музыки [15].
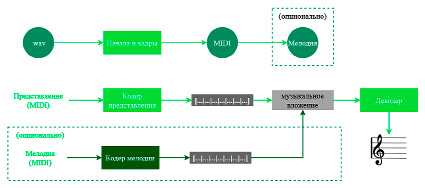
Рис. 4. Технологическая схема самокодера Transformer MuseNet
Заключение
В данной статье были рассмотрены существующие на сегодняшний день модели для генерации музыки, основанные на рекуррентных нейронных сетях генеративных состязательных сетях, вариационных автоэнкодерах и трансформерах.
Библиографическая ссылка
Золотарев А.М., Белов Ю.С. МОДЕЛИ ГЛУБОКОГО ОБУЧЕНИЯ ДЛЯ ГЕНЕРАЦИИ МУЗЫКИ // Научное обозрение. Технические науки. 2024. № 2. С. 18-23;URL: https://science-engineering.ru/ru/article/view?id=1461 (дата обращения: 23.06.2026).
DOI: https://doi.org/10.17513/srts.1461