

 science-review.ru
science-review.ru
Введение
Методология DevOps способствует ускорению доставки изменений в производственные среды через непрерывную интеграцию (continuous intergation, далее по тексту CI), непрерывное развертывание (continuous delivery, далее по тексту CD) и автоматизацию инфраструктурных процессов.
Проблематика, решаемая данным исследованием: низкий уровень описания потенциальных точек внедрения больших языковых моделей (large language models, далее по тексту будет использовано сокращение LLM) в методологию DevOps, блокирующий дополнительные возможности для оптимизации процедур разработки и эксплуатации.
Цель настоящего исследования заключается в определении наиболее перспективных областей применения больших языковых моделей (LLM) в процессах DevOps и оценке влияния их внедрения на повышение продуктивности команды разработчиков и администраторов.
Основные задачи исследования:
- определение потенциала LLM в поддержке основных этапов жизненного цикла разработки, тестирования и поставки ПО;
- оценка преимуществ и недостатков использования LLM в конкретных подходах DevOps;
- выявление факторов, влияющих на успешность внедрения LLM в процессы DevOps;
- формулирование практических рекомендаций по эффективному применению LLM в реальных проектах.
Материалы и методы исследования
Исследование проводилось в компактной DevOps [1] команде (1 Senior и 2 Middle инженера). В качестве основной модели использовалась бесплатная версия GigaChat, а также другие свободно доступные бесплатные версии LLM. Оценка эффективности велась по agile-метрикам [2], с фокусом на трудозатраты, метрики качества выполнения и скорость решения задач.
В результате исследования были получены и сопоставлены метрики выполнения схожих по сложности задач сотрудниками, применяющими LLM и не применяющими. Замер контроля качества производился лидером компетенции. Трудозатраты оценивались всей командой по методологии Scrum [2] во избежание различия в сложности выполнения сравниваемых задач. Время выполнения задач формировалось на основе выгрузки статистики из Jira.
Рассматривались следующие направления работы DevOps инженера: генерация и рефакторинг кода, комментирование и документирование, анализ логов и отладка, конфигурация инфраструктуры, оценка ресурсов и проектирование архитектуры, освоение новых технологий. Для исследования использовались следующие методы: наблюдение, эксперимент, измерение.
Результаты исследования и их обсуждение
Помощь в написании кода. Автоматическая генерация фрагментов кода – одна из важнейших функций LLM. Она ускоряет разработку прототипов, реализацию функций и модернизацию существующих компонентов, сокращая время написания кода на 20–80 %. Основная проблема – сложность оценки качества генерируемого кода инженерами уровня Junior, что требует дополнительной проверки опытными коллегами (уровня Middle, Senior).
Анализ данных, представленных в табл. 1, показывает, что за более короткий период времени LLM выдала код, аналогичный написанному Senior DevOps инженером. Оба результата приемлемы и выполняют поставленную задачу.
Таблица 1
Примеры написанного кода по задаче «Необходимо открыть файл test.txt и распечатать все строки, содержащие FLAG» на языке программирования Python
|
Исполнитель |
Senior DevOps инженер |
LLM |
|
Задача/промпт |
Необходимо открыть файл test.txt и распечатать все строки, содержащие FLAG |
Ты – профессиональный Senior DevOps. Необходимо открыть файл test.txt и распечатать все строки, содержащие FLAG. Используй Python |
|
Результат |
file = open(‘test.txt’) for line in file: if ‘FLAG’ in line: print(line.strip()) |
# Открываем файл test.txt в режиме чтения with open(‘test.txt’, ‘r’) as file: # Читаем все строки файла lines = file.readlines() # Проходим по каждой строке и проверяем наличие слова ‘FLAG’ for line in lines: if ‘FLAG’ in line: print(line.strip()) # Печать строки без символа новой строки |
|
Время |
2 минуты |
20 секунд |
Примечание: составлена автором на основе ответа LLM и программного кода собственной разработки; промпт [3] составлен автором.
Помощь в комментировании. Комментирование кода улучшает его прозрачность и читаемость. Исследование показало, что LLM повышают покрытие кода комментариями на 20–40 %, детально описывая логику и учитывая контекст. Однако требуется контроль инженера, хорошо погруженного в контекст проекта, так как комментарии модели могут требовать коррекции. Качество генерации улучшается при доступе к широкому контексту всего проекта и грамотно сформулированных промптах.
С примером комментирования собственного кода LLM можно ознакомиться в табл. 1.
Пример комментирования кода по промпту «Ты – Senior Java Developer. Добавь комментарии в код» (как контекст был передан код интеграционного теста, написанный автором на Java с использованием фреймворка SpringBoot) [4]:
// Интеграционный тест для HelloController с полной загрузкой контекста Spring Boot
@SpringBootTest
// Включает автоматическое создание экземпляра MockMvc для тестирования веб-эндпоинтов
@AutoConfigureMockMvc
public class HelloControllerTest {
// Автоматически внедряется экземпляр MockMvc для выполнения тестов
@Autowired
private MockMvc mvc;
// Точка входа в тестирование метода getHello контроллера
@Test
public void getHello() throws Exception {
// Отправляем GET-запрос на корень «/» с ожиданием JSON-ответа
mvc.perform(MockMvcRequestBuilders.get(«/»)
.accept(MediaType.APPLICATION_JSON)) // Устанавливаем Accept-заголовок для JSON
.andExpect(status().isOk()) // Проверяем, что статус ответа равен 200 OK
.andExpect(content().string(equalTo(«Greetings from Spring Boot!»))); // Проверяем, что тело ответа соответствует ожидаемому значению
}
}
Представленный фрагмент демонстрирует, как LLM добавила комментарии без отрыва от контекста всего отрывка кода интеграционного теста.
Помощь в дебаге / Анализ логов приложения. Процесс обнаружения и исправления ошибок в коде приложений и скриптов занимает значительную долю рабочего времени разработчиков и инженеров DevOps. Использование LLM помогает упростить этап локализации проблемы и оперативней найти возможные пути ее решения.
Помощь со стороны LLM в анализе причин неисправности сокращает время устранения в несколько раз. Ответ модели, даже в случае отсутствия в нем явной причины возникновения проблемы, позволяет акцентировать внимание инженера на важной информации, которая, в свою очередь, может сыграть решающую роль в локализации и устранении неисправности.
В табл. 2 представлен пример результат анализа лога ошибки с помощью LLM.
Практика показывает, что в случае возникновения подобной ошибки время решения инженером уровня Junior без помощи более квалифицированного коллеги может составить до 1 ч. Столь длительный поиск причин ошибки связан с неоднозначностью трактования сообщения в логе «partially initialized module ‘requests’ has no attribute ‘get’», что, в свою очередь, наводит инженера на неправильный путь решения (поиск потерявшегося атрибута get, проверка кода на правильность, повышение уровня логирования и т.д.).
LLM в данном случае выявила зависимость между названием запускаемого файла и названием стандартной библиотеки Python, что и являлось причиной возникновения ошибки, а также дала рекомендации, как избежать повторения подобных проблем.
Помощь в конфигурации. Конфигурация серверов и сервисов представляет собой трудоемкий и подверженный ошибкам процесс [5]. Использование LLM способно сократить число ошибок, возникающих вследствие применения некорректных настроек. В ходе исследования было проведено сравнение методов конфигурации человеком без и с использованием модели GigaChat, проведена оценка корректности конфигураций. Доля правильных конфигураций на стендах разработки увеличилась на 40 % (> 20 % – только за счет отсутствия орфографических и синтаксических ошибок).
Таблица 2
Пример анализа лога ошибки, с которой часто встречаются новички при запуске приложения, написанного на Python
|
Исходный код |
Файл requests.py import requests url = ‘https://httpbin.org/get’ response = requests.get(url) |
|
Ошибка |
Traceback (most recent call last): File “/home/in2thevoid/Документы/Научная деятельность/Применение LLM в методологии DevOps/requests.py”, line 1, in <module> import requests File “/home/in2thevoid/Документы/Научная деятельность/Применение LLM в методологии DevOps/requests.py», line 4, in <module> response = requests.get(url) ^^^^^^^^^^^^ AttributeError: partially initialized module ‘requests’ has no attribute ‘get’ (most likely due to a circular import) |
|
Промпт |
Ты – профессиональный Python разработчик. Найди причину ошибки |
|
Ответ LLM |
Проблема вызвана конфликтом имен модулей. У вас имеется файл с именем requests.py, который совпадает с названием популярной сторонней библиотеки requests. Из-за этого возникает циклический импорт. Решение: Переименовать файл requests.py в новый уникальный файл (например, my_requests.py) Рекомендация: Лучше избегать совпадения собственных файлов с названиями популярных пакетов Python, чтобы избежать подобных конфликтов. |
|
Время |
10 секунд |
Примечание: составлена автором на основе ответа LLM и программного кода собственной разработки; промпт составлен автором
Таблица 3
Пример конфигурации ingress и service для маршрутизации трафика внутри кластера k8s
|
Промпт |
Ты – Senior DevOps Engineer. Напиши конфигурацию k8s ingress и service, распределяющие трафик на 8 разных сервисов и покрывающие соединение ssl |
|
Результат |
Файл конфигурации ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress ... rules: – host: example.com http: paths: – path: /svc1(/|$)(.*) pathType: Prefix backend: service: name: svc1 port: number: 8080 ... Пример Service ресурса для сервиса svc1 (остальные сервисы аналогичны) apiVersion: v1 kind: Service … ports: – protocol: TCP port: 8080 targetPort: 8080 type: ClusterIP |
|
Время |
< 1 минуты |
Примечание: составлена автором на основе ответа LLM; промпт составлен автором
Таблица 4
Пример очень глубокого рефакторинга кода, написанного на языке программирования Python, выполняющего сортировку «пузырьком»
|
Промпт |
Ты – профессиональный Python разработчик. Проведи рефакторинг и расставь комментарии в коде. Сделай код масштабируемым, вынеси нужные блоки в классы. Классы кратко прокомментируй |
|
Код |
from random import randint N = 10 a = [] for i in range(N): a.append(randint(1, 99)) print(a) for i in range(N-1): for j in range(N-1-i): if a[j] > a[j+1]: a[j], a[j+1] = a[j+1], a[j] print(a) |
|
Код после рефакторинга |
import random class RandomArrayGenerator: «»»Класс для генерации случайного массива»»» def __init__(self, size=10, min_value=1, max_value=99): «»» :param size: размер массива :param min_value: минимальное значение элемента :param max_value: максимальное значение элемента “”” self.size = size self.min_value = min_value self.max_value = max_value def generate(self): “””Генерация случайного массива””” return [random.randint(self.min_value, self.max_value) for _ in range(self.size)] class BubbleSorter: «»»Класс для сортировки массива методом пузырьковой сортировки»»» def sort(self, array): «»» Сортируем массив методом пузырьковой сортировки :param array: массив для сортировки :return: отсортированный массив “”” n = len(array) for i in range(n – 1): for j in range(n – 1 – i): if array[j] > array[j + 1]: array[j], array[j + 1] = array[j + 1], array[j] return array if __name__ == “__main__”: generator = RandomArrayGenerator(size=10) unsorted_array = generator.generate() print(f»Несортированный массив:\n{unsorted_array}») bubble_sorter = BubbleSorter() sorted_array = bubble_sorter.sort(unsorted_array[:]) # Создаем копию массива, чтобы сохранить оригинал print(f»Сортированный массив:\n{sorted_array}») |
|
Время |
< 1 минуты |
Примечание: составлена автором на основе ответа LLM и программного кода собственной разработки; промпт составлен автором
Полная автоматизация процесса пока невозможна ввиду сложности требований и необходимости контроля со стороны персонала. Поскольку от скорости конфигурации стендов разработки и тестирования напрямую зависит скорость конфигурации промышленных стендов, можно выявить прямую зависимость прироста скорости вывода новой функциональности и предоставления ее конечным пользователям (что, по факту, является уменьшением бизнес-метрики time-to-market [6]). В табл. 3 представлен пример конфигурации сети кластера k8s [7], составленной LLM.
Помощь в освоении технологий. Частое обновление техстека и версий ПО увеличивает нагрузку на команду DevOps, стимулируя обучение. LLM могут помочь, давая советы и подсказки. Однако неправильное использование LLM может усложнить процесс обучения: отсутствие нужного контекста ведет к выдаче некорректных рекомендаций. Например, запросы о нетипичных или новых сочетаниях технологий, таких как Gradle 8.8 с Kotlin [8], часто приводят к выдаче некорректных ответов. Для митигации последствий рисков некачественного обучения рекомендуется использование микротестирования [9], изучение официальных курсов и документации в сочетании с возможностями LLM (объяснения кода, его доработка или краткий пересказ статей и параграфов документации).
Помощь в рефакторинге. Рефакторинг [10] существующего кода является важной частью поддержания высокого качества программного продукта (в контексте DevOps – пайплайна и настроек инфраструктура). Использование LLM позволяет автоматизировать создание небольших исправлений и оптимизаций, снижая нагрузку на команду. Также LLM позволяет полностью переписать большие объемы кода, но требует контроля и тестирования со стороны команды. Правильно составленный промпт позволяет существенно улучшить уровень рефакторинга LLM, пример показан в табл. 4.
В контексте данной статьи автор не будет углубляться в качество кода и его масштабируемость. Пример выше показывает, что во время рефакторинга [10] код не обязательно уменьшится в объеме, но, при правильно составленном промпте, может стать более масштабируемым/быстрым/экономным к ресурсам и т.д. В конкретном случае LLM была поставлена задача перевести код в парадигму объектно-ориентированного программирования, с чем она успешно справилась.
Выбор архитектурного решения. При выборе архитектурных решений должны быть учтены ключевые факторы: бизнес-требования, технические характеристики, бюджет и сроки реализации [11]. LLM помогают принять оптимальное решение, предлагая рекомендации на основе большого количества данных. Передача на вход LLM контекста инфраструктуры, языков программирования, протоколов и бизнес-требований позволяет ей строить схемы концептуальной и детальной архитектуры и предлагать несколько альтернативных вариантов. В DevOps данная функциональность может быть применена для выбора инфраструктурных решений, проектирования пайплайнов [12] и каналов передачи данных [13].
Таблица 5
Подсчет ресурсов приложения и кластера k8s
|
Промпт |
Ты – Senior Solution Architect. Посчитай ресурсы (cpu, ram, реплики), необходимые сервису, написанному на rust, использующему базу данных postgres и отвечающему на 100000 запросов в секунду. Сервис расположен в k8s. Также посчитай ресурсы кластера k8s и базы данных postgres. Запас по нагрузке – 30 % |
|
Результат |
Окончательные оценки ресурсов: Rust-сервис CPU130 RAM1.3 GB, Реплика Rust-сервиса CPU43 RAM 0.43 GB, База данных Postgres CPU4, RAM 16 GB Исходя из этих оценок, минимальная конфигурация узлов k8s-кластера может выглядеть следующим образом: Количество реплик Rust-сервиса: 3 Ресурсы узла k8s-кластера: CPU: 150 (для обслуживания всех реплик и самой базы данных) RAM: 20 GB (суммарно для трех реплик и одной базы данных). Это лишь ориентировочные расчеты, реальная потребность может варьироваться в зависимости от архитектуры сервиса, характеристик оборудования и инфраструктуры. Рекомендуется провести стресс-тестирование и профилирование перед внедрением. |
|
Время |
30 секунд |
Примечание: составлена автором на основе ответа LLM; промпт составлен автором
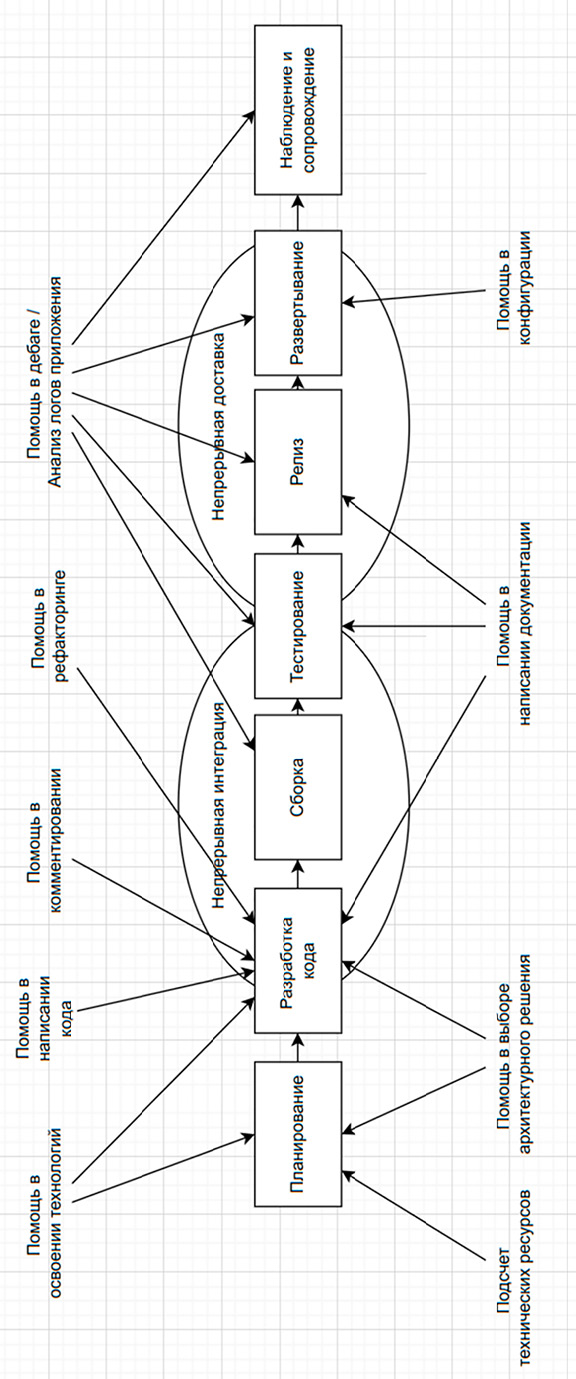
Схема точек потенциально целесообразного внедрения LLM в этапы процесса методологии DevOps Примечание: составлен автором на основе проведенного исследования, собранных данных и сделанных выводов
Подсчет технических ресурсов. Оценка вычислительных ресурсов – важная задача DevOps на начальном этапе разработки. LLM эффективно помогает в расчете потребности, используя исторические статистические данные и прогнозируя потенциальные нагрузки. Поскольку нагрузочное тестирование [14] на ранних этапах разработки приложения, как правило, отсутствует, расчет носит предварительный характер. Точность расчета LLM на данном этапе не критична, так как дальнейшая коррекция осуществляется по результатам реального НТ. Пример расчета ресурсов, сделанного LLM, представлен в табл. 5. Помощь в написании документации. Документация является неотъемлемой частью любого проекта, обеспечивающей передачу знаний внутри команды. LLM способны быстро формировать документацию на основании кода и архитектуры. Проведенное исследование подтверждает целесообразность написания документации с помощью LLM, но только при контроле результата командой. Языковые модели хорошо описывают не только свой код, но и код, переданный в контексте, отлично могут описать часть «легаси» кода [15], сокращая время на его исследование, а также хорошо обогащают уже существующую документацию примерами и уточнениями.
Как итог, автором составлена схема точек целесообразного внедрения языковых моделей в этапы процесса методологии DevOps. Схема представлена на рисунке.
Заключение
Проведенное исследование выявило значительный потенциал больших языковых моделей (LLM) в повышении эффективности практик DevOps. Получены положительные результаты во всех выбранных направлениях. Результатом стали снижение среднего времени выполнения задач, повышение качества артефактов и автоматизация рутинных задач. Также выявлены и риски, связанные с точностью рекомендаций и корректностью выдачи ответов. Таким образом, можно сделать вывод о том, что внедрение LLM в методологию DevOps является целесообразным и эффективным и позволяет добиться заметной оптимизации работы команды, а следовательно, и сокращения time-to-market и количества инцидентов, что на дистанции использования положительно повлияет на финансовый эффект как DevOps подразделения, так и программного продукта в целом.
Конфликт интересов
Библиографическая ссылка
Лелейкин С.С. Применение больших языковых моделей (Large Language Models) в методологии DevOps // Научное обозрение. Технические науки. 2025. № 5. С. 25-32;URL: https://science-engineering.ru/ru/article/view?id=1523 (дата обращения: 01.07.2026).
DOI: https://doi.org/10.17513/srts.1523