

 science-review.ru
science-review.ru
Получение новых знаний практически в любой отрасли науки невозможно представить без сбора и обработки статистических данных.
Обработка данных наблюдений или экспериментов осуществляется с целью вывода зависимостей, позволяющих описать исследуемые процессы (эмпирико-теоретический метод исследований). В настоящее время анализ данных превратился в отдельную науку на стыке математики и информатики.
Известно множество способов анализа данных: регрессионный, канонический, кластерный, дискриминантный, корреляционный, факторный и множество других [1; 2]. При выполнении каждого типа анализа преследуются разные цели.
В последнее время широкое распространение получил нейросетевой анализ, основанный на имитации работы нервной системы человека. Для осуществления данного метода обработки данных необходимо создать так называемую нейронную сеть, а затем обучить её на исторических данных. Модель, полученная в результате обучения, при правильной организации этого процесса обладает свойствами предсказания событий с определённой высокой долей вероятности.
Целью данной работы является разработка программы, реализующей один из вариантов нейронной сети, позволяющей на раннем этапе прогнозировать наличие либо отсутствие заболеваний сердца у пациентов по известным параметрам их исследования в центре здоровья.
При этом также ставится задача демонстрации порядка работы с модулем нейросетевого программирования Keras, реализующим метод «глубокого обучения» (deep learning). Также используются другие библиотеки языка Python. Для «тренировки» сети набор экспериментальных данных обрабатывается специальным образом.
После обучения нейронной сети необходимо решить задачу оценки качества созданной на её основе модели исследуемого процесса возникновения заболеваний.
Материалы и методы исследования
Часто традиционными методами не удаётся описать отклик системы на воздействие входных факторов, но с этой задачей во многих случаях может справиться обучаемая нейронная сеть. Способ построения нейронной сети напоминает организацию нервной системы человека из нейронов [3].
Рассмотрим, например, использование нейронной сети при проверке предполагаемого диагноза больного на основании анализа показателей клинических исследований. Значения физиологических показателей подаются на нейроны первого слоя сети, обрабатываются, и уже в усиленном или ослабленном виде передаются на следующий слой. Таких слоёв необходимо создать несколько (входной, выходной и промежуточные). При обучении сети по факторам и известным результатам их воздействия на систему формируются коэффициенты усиления или ослабления сигналов межнейронными связями. Если система должна выдать значение одного результата (отсутствия или наличия заболевания), то последний слой такой сети состоит только из одного нейрона, на котором и вырабатывается отклик – ответ системы, необходимый исследователю.
При создании нейронной сети ключевыми моментами, от которых зависит качество дальнейшего прогнозирования, являются её архитектура (количество слоёв и нейронов в каждом слое, их взаимные связи или их отсутствие), набор факторов для обучения и формирования прогноза, а также способ обучения сети.
Особенности любой научной работы в первую очередь определяются составом исходных данных для исследования. В нашем случае были использованы открытые базы данных по болезням сердца в некоторых странах, хорошо подходящие для целей машинного обучения [4]. В них приводятся только данные анкетирования и медицинских замеров, без указания личных данных пациентов.
Эти данные собраны по следующим медицинским учреждениям:
1. Кливлендская клиника.
2. Венгерский институт кардиологии, Будапешт.
3. Ветеранский медицинский центр, Лонг-Бич, Калифорния.
4. Университетская больница, Цюрих, Швейцария.
По каждому учреждению для каждого пациента собрано по 74 параметра, из которых для диагностики болезней сердца имеют смысл только 14 (причём многие из них выражены условными обозначениями, отображающими показатель не количественно, а качественно), а именно: возраст, пол, тип грудной боли, кровяное давление в покое, холестерин в крови, сахар в крови, результаты кардиографии, частота сердечного ритма, стенокардия при физической нагрузке, наклон пика ST-сегмента на кардиограмме при нагрузке, форма пика ST-сегмента, количество крупных сосудов (0–3), окрашенных при флюорографии, тип сердечного ритма. Результат (14-й параметр) выражен бинарным образом: 0 – риск сердечных заболеваний незначительный, 1 – риск сердечных заболеваний высокий (сужение диаметров крупных сосудов превышает 50 %).
Из 4 баз данных для исследования выбрана наибольшая по количеству записей (объёму) – база Венгерского института кардиологии. Для обучения нейронной сети не использовались столбцы 10–13, в которых практически отсутствуют данные (они имеются лишь по некоторым пациентам). Кроме того, исключено небольшое количество строк, в которых часть записей в столбцах 1–9 отсутствует. В результате такой предварительной обработки базы в ней осталась 261 строка. Для обучения базы использовались столбцы 1–9 с факторами и столбец 14 с результатами.
Для загрузки файла данных и перемешивания строк базы данных случайным образом (для исключения ложного обучения) использована библиотека Numpy [5]. Затем для реализации алгоритма работы с нейронной сетью использован современный высокоуровневый модуль Keras, обладающий широкими возможностями, написанный на языке Python и являющийся надстройкой для модуля более низкого уровня организации Tensorflow (так называемого фреймворка).
Рассмотрим порядок создания нейронной сети и работы с ним с помощью модуля Keras.
1. Указываем столбцы факторов – входных параметров X (с 1 по 9) и столбец результата – целевой переменной Y (14-й).
2. Выбираем модель нейронной сети Sequential (прямого распространения СПР) – с последовательным соединением нейронных слоев, в которой информация проходит только в прямом направлении. Как показала практика, такая сеть хорошо подходит для задач классификации и идентификации событий, подобных рассматриваемой.
3. Определяем слои нейронной сети. Входной слой имеет размерность 9 согласно количеству действующих факторов. Число нейронов выбрано достаточно условно равным 12 (в результате оптимизации сети для достижения наилучших результатов предсказаний). Далее добавлено ещё 3 слоя, состоящих соответственно из 15, 8 и 10 нейронов.
Созданная топология сети отображена средствами графических библиотек Graphviz и Pydot для Python [5] и показана на рис. 1.
На данном рисунке наглядно видно количество слоёв, нейронов в каждом слое, способ взаимного соединения слоёв, тип каждого слоя.
Тип активизации сетей выбран Rectified linear units (ReLU), считающийся в настоящее время наиболее подходящим для сетей с глубоким обучением. Выходной слой имеет один нейрон, т.к. целью сети является идентификация только одного параметра, для активизации этого слоя использован метод активизации с помощью сигмоидной функции, хорошо фильтрующей шумы.
4. Для возможности использования сеть нужно скомпилировать. Для этого использован популярный метод оптимизации Adam (полное название «метод адаптивной инерции») [6].
5. Выбираем метод обучения сети fit, включающий в себя разбиение данных на тренировочные (в данном случае матрица X из столбцов 1–9) и валидационные (матрица-вектор Y из столбца 14). Также задаётся количество проходов (эпох) обучения и количество строк для одного шага обучения. В дальнейшем будет рассмотрено влияние количество эпох на качество обучения созданной сети.
6. В конце программы задаём функцию evaluate модуля Keras, оценивающую точность прогноза по созданной модели и вывода значения точности на экран.
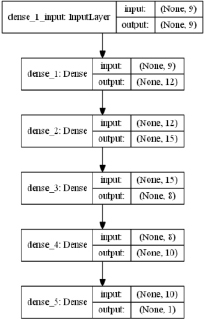
Рис. 1. Топография созданной нейронной сети
Результаты исследования и их обсуждение
Одной из целей исследований была оценка влияния количества эпох обучения на точность достигаемого результата. Нейросеть обучалась последовательно по 100 эпохам 500 раз (итого по 50000 эпохам), после каждого обучения оценивалась точность прогнозирования и заносилась в массив. Созданный массив результатов оценки точности в процентах в зависимости от количества эпох выведен в графическом виде с помощью библиотеки Matplotlib на рис. 2.
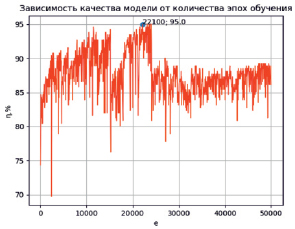
Рис. 2. Зависимость качества прогнозирования нейросетью от количества эпох обучения
Из рис. 2 можно сделать вывод, что качество обучения сети нестабильно в зависимости от количества эпох, хотя явно недообученная система (с количеством эпох до 1000) даёт более низкую точность прогноза. Нестабильность результата обучения можно объяснить снижением и повышением корреляционной связи между количеством нейронов в слоях и типом использованных слоёв и количеством данных для обучения при их варьировании. Максимальная точность прогноза наблюдается вблизи количества эпох 10000 и 20000. С помощью функции max библиотеки Numpy найдено максимально достигнутое качество прогноза 95 % при количестве эпох обучения 22100. Поэтому такое количество эпох и рекомендуется использовать для обучения созданной нейросети.
С использованием описанных методов организации, обучения и оценивания нейронных сетей можно создавать сети различной топографии и подбирать из них подходящие наилучшим образом для решения поставленных задач. В случае необходимости кроме описанных библиотек в программе на Python можно использовать и дополнительные, специализированные библиотеки [7].
В данной работе рассмотрена методика работы с нейронными сетями с использованием библиотек языка Python. К настоящему времени эта задача является нетривиальной, так как язык Python и дополнительные модули для работы с ним динамично развиваются, появляются новые команды, изменяется синтаксис. Это создает определённые сложности в освоении этого универсального языка, но одновременно сильно расширяет его возможности.
В частности, для обеспечения гибкости работы с нейросетями язык Python с подключением модуля глубокого обучения Keras и прочих дополнительных модулей обладает следующими неоспоримыми преимуществами, одновременного сочетания которых нет в других программных продуктах [8]:
– модульность, компактность, расши- ряемость;
– лёгкость освоения неспециалистами;
– множество инструментов работы с нейронными сетями;
– реализация принципов глубокого обучения, получившего известность в последнее время и способного создавать прогнозы для более широкого круга явлений, чем традиционные способы обучения (такие как ненаправленная графическая модель);
– возможность эффективного использования графических процессоров (видеокарт) для вычислений;
– широкие возможности визуализации результатов с использованием модуля Matplotlib.
Данная статья иллюстрирует лишь частный случай – пример работы с модулем глубокого обучения Keras для распознавания заболеваний. Кроме этой цели, модуль Keras всё чаще начинают использовать при машинном переводе текстов, распознавании условных графических обозначений, образов и даже людей по фотографиям [9].
Заключение
Из выполненной и описанной работы можно сформулировать следующие особенности работы с модулем Keras, которые необходимо учитывать для дальнейшей оптимизации работы с ним:
– важно правильно определить состав исходных факторов для обучения и прогноза, действительно оказывающих влияние на результат;
– необходимо выбрать тип и топографию нейронной сети, наиболее легко и быстро обучаемой и дающей наиболее точный прогноз;
–целесообразно выбрать наиболее эффективный метод компиляции сети из всех существующих, которые со временем совершенствуются;
– обязательно нужно подобрать количество эпох обучения, причём в этом случае важно не получить недообучения или переобучения сети, т.к. в этих случаях точность прогнозирования с её помощью уменьшается. Оптимальное количество эпох можно подобрать методом, описанным в данной статье.
Принципы использования модуля глубокого обучения Keras, изложенные в статье, можно применить для создания нейросетей с целью классификации многих других событий и объектов [10].
Библиографическая ссылка
Ильичев В.Ю., Юрик Е.А. ОБРАБОТКА СТАТИСТИЧЕСКИХ ДАННЫХ МЕТОДОМ ГЛУБОКОГО ОБУЧЕНИЯ С ИСПОЛЬЗОВАНИЕМ МОДУЛЯ KERAS // Научное обозрение. Технические науки. 2020. № 5. С. 16-20;URL: https://science-engineering.ru/ru/article/view?id=1311 (дата обращения: 24.06.2026).